 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMUR Neural Network Dataset: Towards Seamless AutoML
Apr 14, 2025Neural networks are fundamental in artificial intelligence, driving progress in computer vision and natural language processing. High-quality datasets are crucial for their development, and there is growing interest in datasets composed of neural networks themselves to support benchmarking, automated machine learning (AutoML), and model analysis. We introduce LEMUR, an open source dataset of neural network models with well-structured code for diverse architectures across tasks such as object detection, image classification, segmentation, and natural language processing. LEMUR is primarily designed to enable fine-tuning of large language models (LLMs) for AutoML tasks, providing a rich source of structured model representations and associated performance data. Leveraging Python and PyTorch, LEMUR enables seamless extension to new datasets and models while maintaining consistency. It integrates an Optuna-powered framework for evaluation, hyperparameter optimization, statistical analysis, and graphical insights. LEMUR provides an extension that enables models to run efficiently on edge devices, facilitating deployment in resource-constrained environments. Providing tools for model evaluation, preprocessing, and database management, LEMUR supports researchers and practitioners in developing, testing, and analyzing neural networks. Additionally, it offers an API that delivers comprehensive information about neural network models and their complete performance statistics with a single request, which can be used in experiments with code-generating large language models. The LEMUR will be released as an open source project under the MIT license upon acceptance of the paper.
Optuna vs Code Llama: Are LLMs a New Paradigm for Hyperparameter Tuning?
Apr 08, 2025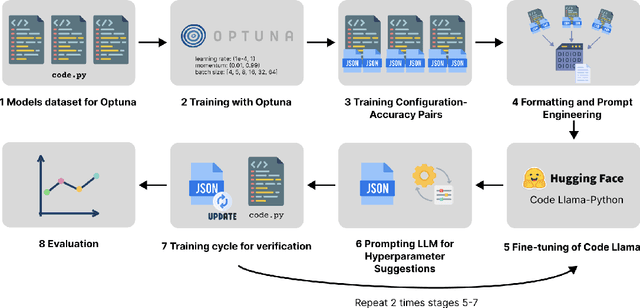



Optimal hyperparameter selection is critical for maximizing neural network performance, especially as models grow in complexity. This work investigates the viability of using large language models (LLMs) for hyperparameter optimization by employing a fine-tuned version of Code Llama. Through parameter-efficient fine-tuning using LoRA, we adapt the LLM to generate accurate and efficient hyperparameter recommendations tailored to diverse neural network architectures. Unlike traditional methods such as Optuna, which rely on exhaustive trials, the proposed approach achieves competitive or superior results in terms of Root Mean Square Error (RMSE) while significantly reducing computational overhead. Our approach highlights that LLM-based optimization not only matches state-of-the-art methods like Tree-structured Parzen Estimators but also accelerates the tuning process. This positions LLMs as a promising alternative to conventional optimization techniques, particularly for rapid experimentation. Furthermore, the ability to generate hyperparameters in a single inference step makes this method particularly well-suited for resource-constrained environments such as edge devices and mobile applications, where computational efficiency is paramount. The results confirm that LLMs, beyond their efficiency, offer substantial time savings and comparable stability, underscoring their value in advancing machine learning workflows. All generated hyperparameters are included in the LEMUR Neural Network (NN) Dataset, which is publicly available and serves as an open-source benchmark for hyperparameter optimization research.