 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCA: Memory-Centric, Adaptive Execution for Multi-Tenant Deep Neural Networks
May 10, 2023



Driven by the wide adoption of deep neural networks (DNNs) across different application domains, multi-tenancy execution, where multiple DNNs are deployed simultaneously on the same hardware, has been proposed to satisfy the latency requirements of different applications while improving the overall system utilization. However, multi-tenancy execution could lead to undesired system-level resource contention, causing quality-of-service (QoS) degradation for latency-critical applications. To address this challenge, we propose MoCA, an adaptive multi-tenancy system for DNN accelerators. Unlike existing solutions that focus on compute resource partition, MoCA dynamically manages shared memory resources of co-located applications to meet their QoS targets. Specifically, MoCA leverages the regularities in both DNN operators and accelerators to dynamically modulate memory access rates based on their latency targets and user-defined priorities so that co-located applications get the resources they demand without significantly starving their co-runners. We demonstrate that MoCA improves the satisfaction rate of the service level agreement (SLA) up to 3.9x (1.8x average), system throughput by 2.3x (1.7x average), and fairness by 1.3x (1.2x average), compared to prior work.
ProTuner: Tuning Programs with Monte Carlo Tree Search
May 27, 2020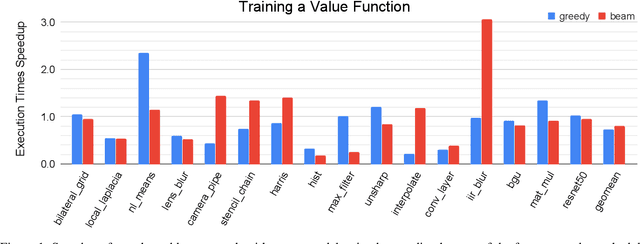

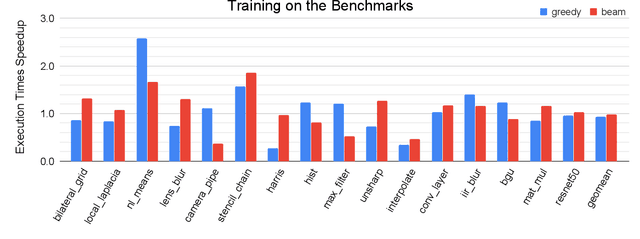
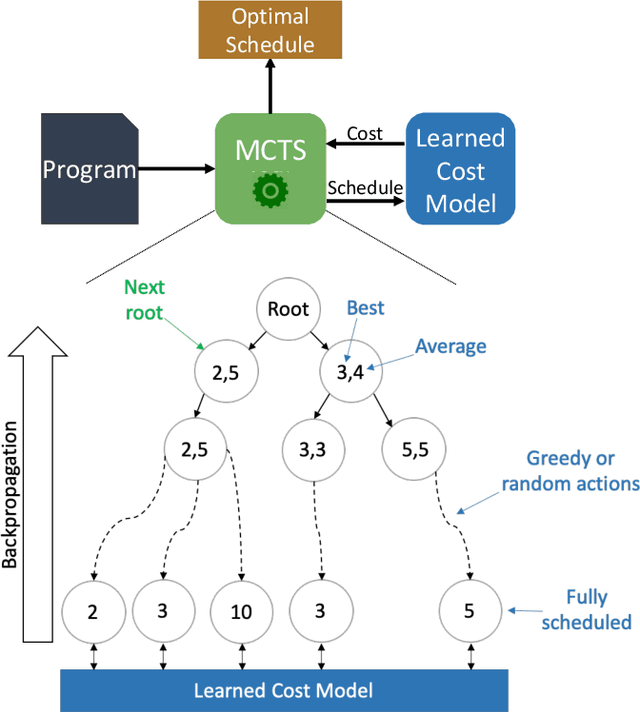
We explore applying the Monte Carlo Tree Search (MCTS) algorithm in a notoriously difficult task: tuning programs for high-performance deep learning and image processing. We build our framework on top of Halide and show that MCTS can outperform the state-of-the-art beam-search algorithm. Unlike beam search, which is guided by greedy intermediate performance comparisons between partial and less meaningful schedules, MCTS compares complete schedules and looks ahead before making any intermediate scheduling decision. We further explore modifications to the standard MCTS algorithm as well as combining real execution time measurements with the cost model. Our results show that MCTS can outperform beam search on a suite of 16 real benchmarks.