 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks
Paper and Code

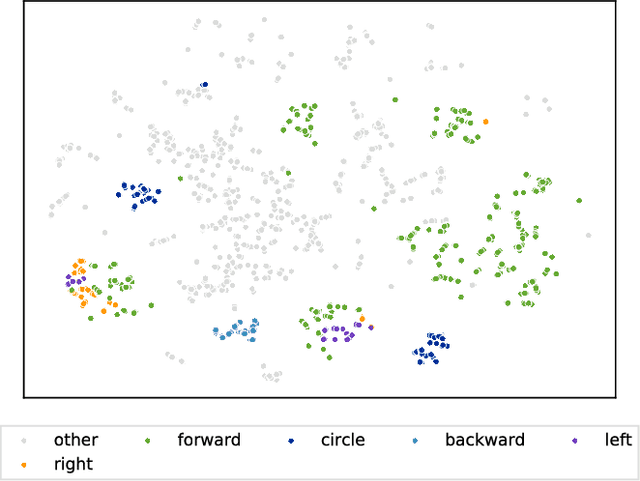

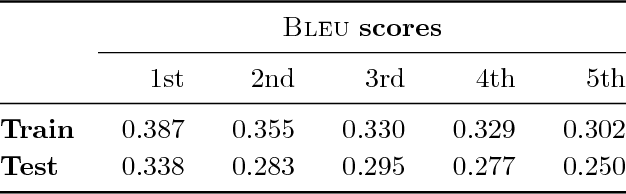
Linking human whole-body motion and natural language is of great interest for the generation of semantic representations of observed human behaviors as well as for the generation of robot behaviors based on natural language input. While there has been a large body of research in this area, most approaches that exist today require a symbolic representation of motions (e.g. in the form of motion primitives), which have to be defined a-priori or require complex segmentation algorithms. In contrast, recent advances in the field of neural networks and especially deep learning have demonstrated that sub-symbolic representations that can be learned end-to-end usually outperform more traditional approaches, for applications such as machine translation. In this paper we propose a generative model that learns a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks (RNNs) and sequence-to-sequence learning. Our approach does not require any segmentation or manual feature engineering and learns a distributed representation, which is shared for all motions and descriptions. We evaluate our approach on 2,846 human whole-body motions and 6,187 natural language descriptions thereof from the KIT Motion-Language Dataset. Our results clearly demonstrate the effectiveness of the proposed model: We show that our model generates a wide variety of realistic motions only from descriptions thereof in form of a single sentence. Conversely, our model is also capable of generating correct and detailed natural language descriptions from human motions.