 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Learning for Channel Allocation in IoT Networks over Unlicensed Bandwidth as a Contextual Multi-player Multi-armed Bandit Game
Paper and Code
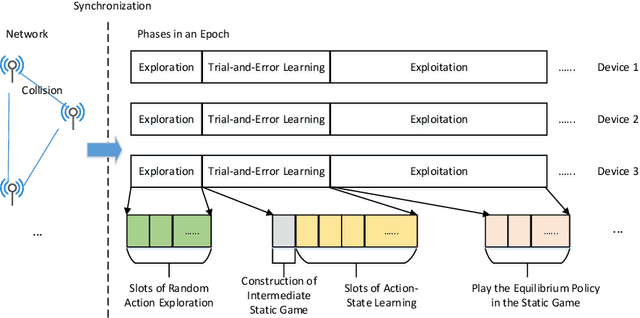
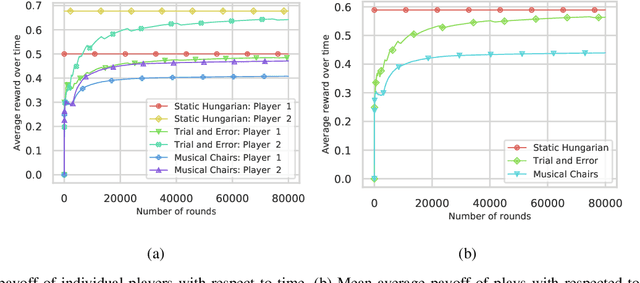
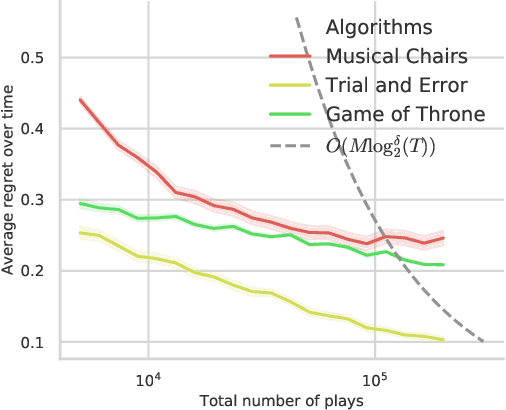
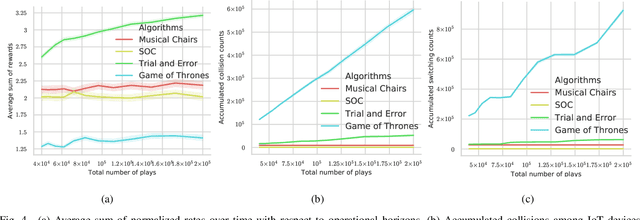
We study a decentralized channel allocation problem in an ad-hoc Internet of Things (IoT) network underlaying on a spectrum licensed to an existing wireless network. In the considered IoT network, the impoverished computation capability and the limited antenna number on the IoT devices make them difficult to acquire the Channel State Information (CSI) for the multi-channels over the shared spectrum. In addition, in practice, the unknown patterns of the licensed users' transmission activities and the time-varying CSI due to fast fading or mobility of the IoT devices can also cause stochastic changes in the channel quality. Therefore, decentralized IoT links are expected to learn their channel statistics online based on the partial observations, while acquiring no information about the channels that they are not operating on. Meanwhile, they also have to reach an efficient, collision-free solution of channel allocation on the basis of limited coordination or message exchange. Our study maps this problem into a contextual multi-player, multi-arm bandit game, for which we propose a purely decentralized, three-stage policy learning algorithm through trial-and-error. Our theoretical analysis shows that the proposed learning algorithm guarantees the IoT devices to jointly converge to the social-optimal channel allocation with a sub-linear (i.e., polylogarithmic) regret with respect to the operational time. Simulation results demonstrate that the proposed algorithm strikes a good balance between efficient channel allocation and network scalability when compared with the other state-of-the-art distributed multi-armed bandit algorithms.