 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWirelessBench: A Tolerance-Aware LLM Agent Benchmark for Wireless Network Intelligence
Mar 22, 2026LLM agents are emerging as a key enabler for autonomous wireless network management. Reliably deploying them, however, demands benchmarks that reflect real engineering risk. Existing wireless benchmarks evaluate single isolated capabilities and treat all errors uniformly, missing both cascaded-chain failures and catastrophic unit confusions (\textit{e.g.}, dB vs.\ dBm). We present \wb{}, the first tolerance-aware, tool-integrated benchmark for LLM-based wireless agents. \wb{} is organized as a three-tier cognitive hierarchy: domain knowledge reasoning (WCHW, 1{,}392 items), intent-driven resource allocation (WCNS, 1{,}000 items), and proactive multi-step decisions under mobility (WCMSA, 1{,}000 items). Moreover, \wb{} is established on three design principles: \emph{(i)}~tolerance-aware scoring with catastrophic-error detection; \emph{(ii)}~tool-necessary tasks requiring a 3GPP-compliant ray-tracing query for channel quality; and \emph{(iii)}~Chain-of-Thought (CoT)-traceable items, where every benchmark item ships with a complete CoT trajectory enabling fine-grained diagnosis of where in the reasoning chain an agent fails. Our numerical results show that the direct-prompting model (GPT-4o) scores $68\%$, trailing a tool-integrated agent ($84.64\%$) by $16.64$\,pp; $23\%$ of errors are catastrophic failures invisible to exact-match metrics. More importantly, the hierarchy decomposes errors into four actionable diagnostic categories that flat evaluation cannot reveal. Code and data: https://wirelessbench.github.io/.
Agentic Peer-to-Peer Networks: From Content Distribution to Capability and Action Sharing
Mar 04, 2026The ongoing shift of AI models from centralized cloud APIs to local AI agents on edge devices is enabling \textit{Client-Side Autonomous Agents (CSAAs)} -- persistent personal agents that can plan, access local context, and invoke tools on behalf of users. As these agents begin to collaborate by delegating subtasks directly between clients, they naturally form \emph{Agentic Peer-to-Peer (P2P) Networks}. Unlike classic file-sharing overlays where the exchanged object is static, hash-indexed content (e.g., files in BitTorrent), agentic overlays exchange \emph{capabilities and actions} that are heterogeneous, state-dependent, and potentially unsafe if delegated to untrusted peers. This article outlines the networking foundations needed to make such collaboration practical. We propose a plane-based reference architecture that decouples connectivity/identity, semantic discovery, and execution. Besides, we introduce signed, soft-state capability descriptors to support intent- and constraint-aware discovery. To cope with adversarial settings, we further present a \textit{tiered verification} spectrum: Tier~1 relies on reputation signals, Tier~2 applies lightweight canary challenge-response with fallback selection, and Tier~3 requires evidence packages such as signed tool receipts/traces (and, when applicable, attestation). Using a discrete-event simulator that models registry-based discovery, Sybil-style index poisoning, and capability drift, we show that tiered verification substantially improves end-to-end workflow success while keeping discovery latency near-constant and control-plane overhead modest.
WirelessAgent++: Automated Agentic Workflow Design and Benchmarking for Wireless Networks
Feb 28, 2026The integration of large language models (LLMs) into wireless networks has sparked growing interest in building autonomous AI agents for wireless tasks. However, existing approaches rely heavily on manually crafted prompts and static agentic workflows, a process that is labor-intensive, unscalable, and often suboptimal. In this paper, we propose WirelessAgent++, a framework that automates the design of agentic workflows for various wireless tasks. By treating each workflow as an executable code composed of modular operators, WirelessAgent++ casts agent design as a program search problem and solves it with a domain-adapted Monte Carlo Tree Search (MCTS) algorithm. Moreover, we establish WirelessBench, a standardized multi-dimensional benchmark suite comprising Wireless Communication Homework (WCHW), Network Slicing (WCNS), and Mobile Service Assurance (WCMSA), covering knowledge reasoning, code-augmented tool use, and multi-step decision-making. Experiments demonstrate that \wap{} autonomously discovers superior workflows, achieving test scores of $78.37\%$ (WCHW), $90.95\%$ (WCNS), and $97.07\%$ (WCMSA), with a total search cost below $\$ 5$ per task. Notably, our approach outperforms state-of-the-art prompting baselines by up to $31\%$ and general-purpose workflow optimizers by $11.1\%$, validating its effectiveness in generating robust, self-evolving wireless agents. The code is available at https://github.com/jwentong/WirelessAgent-R2.
Bridging Visual and Wireless Sensing: A Unified Radiation Field for 3D Radio Map Construction
Jan 27, 2026The emerging applications of next-generation wireless networks (e.g., immersive 3D communication, low-altitude networks, and integrated sensing and communication) necessitate high-fidelity environmental intelligence. 3D radio maps have emerged as a critical tool for this purpose, enabling spectrum-aware planning and environment-aware sensing by bridging the gap between physical environments and electromagnetic signal propagation. However, constructing accurate 3D radio maps requires fine-grained 3D geometric information and a profound understanding of electromagnetic wave propagation. Existing approaches typically treat optical and wireless knowledge as distinct modalities, failing to exploit the fundamental physical principles governing both light and electromagnetic propagation. To bridge this gap, we propose URF-GS, a unified radio-optical radiation field representation framework for accurate and generalizable 3D radio map construction based on 3D Gaussian splatting (3D-GS) and inverse rendering. By fusing visual and wireless sensing observations, URF-GS recovers scene geometry and material properties while accurately predicting radio signal behavior at arbitrary transmitter-receiver (Tx-Rx) configurations. Experimental results demonstrate that URF-GS achieves up to a 24.7% improvement in spatial spectrum prediction accuracy and a 10x increase in sample efficiency for 3D radio map construction compared with neural radiance field (NeRF)-based methods. This work establishes a foundation for next-generation wireless networks by integrating perception, interaction, and communication through holistic radiation field reconstruction.
Intelligent Channel Allocation for IEEE 802.11be Multi-Link Operation: When MAB Meets LLM
Jun 05, 2025WiFi networks have achieved remarkable success in enabling seamless communication and data exchange worldwide. The IEEE 802.11be standard, known as WiFi 7, introduces Multi-Link Operation (MLO), a groundbreaking feature that enables devices to establish multiple simultaneous connections across different bands and channels. While MLO promises substantial improvements in network throughput and latency reduction, it presents significant challenges in channel allocation, particularly in dense network environments. Current research has predominantly focused on performance analysis and throughput optimization within static WiFi 7 network configurations. In contrast, this paper addresses the dynamic channel allocation problem in dense WiFi 7 networks with MLO capabilities. We formulate this challenge as a combinatorial optimization problem, leveraging a novel network performance analysis mechanism. Given the inherent lack of prior network information, we model the problem within a Multi-Armed Bandit (MAB) framework to enable online learning of optimal channel allocations. Our proposed Best-Arm Identification-enabled Monte Carlo Tree Search (BAI-MCTS) algorithm includes rigorous theoretical analysis, providing upper bounds for both sample complexity and error probability. To further reduce sample complexity and enhance generalizability across diverse network scenarios, we put forth LLM-BAI-MCTS, an intelligent algorithm for the dynamic channel allocation problem by integrating the Large Language Model (LLM) into the BAI-MCTS algorithm. Numerical results demonstrate that the BAI-MCTS algorithm achieves a convergence rate approximately $50.44\%$ faster than the state-of-the-art algorithms when reaching $98\%$ of the optimal value. Notably, the convergence rate of the LLM-BAI-MCTS algorithm increases by over $63.32\%$ in dense networks.
WRF-GS: Wireless Radiation Field Reconstruction with 3D Gaussian Splatting
Dec 06, 2024Wireless channel modeling plays a pivotal role in designing, analyzing, and optimizing wireless communication systems. Nevertheless, developing an effective channel modeling approach has been a longstanding challenge. This issue has been escalated due to the denser network deployment, larger antenna arrays, and wider bandwidth in 5G and beyond networks. To address this challenge, we put forth WRF-GS, a novel framework for channel modeling based on wireless radiation field (WRF) reconstruction using 3D Gaussian splatting. WRF-GS employs 3D Gaussian primitives and neural networks to capture the interactions between the environment and radio signals, enabling efficient WRF reconstruction and visualization of the propagation characteristics. The reconstructed WRF can then be used to synthesize the spatial spectrum for comprehensive wireless channel characterization. Notably, with a small number of measurements, WRF-GS can synthesize new spatial spectra within milliseconds for a given scene, thereby enabling latency-sensitive applications. Experimental results demonstrate that WRF-GS outperforms existing methods for spatial spectrum synthesis, such as ray tracing and other deep-learning approaches. Moreover, WRF-GS achieves superior performance in the channel state information prediction task, surpassing existing methods by a significant margin of more than 2.43 dB.
WirelessAgent: Large Language Model Agents for Intelligent Wireless Networks
Sep 12, 2024


Wireless networks are increasingly facing challenges due to their expanding scale and complexity. These challenges underscore the need for advanced AI-driven strategies, particularly in the upcoming 6G networks. In this article, we introduce WirelessAgent, a novel approach leveraging large language models (LLMs) to develop AI agents capable of managing complex tasks in wireless networks. It can effectively improve network performance through advanced reasoning, multimodal data processing, and autonomous decision making. Thereafter, we demonstrate the practical applicability and benefits of WirelessAgent for network slicing management. The experimental results show that WirelessAgent is capable of accurately understanding user intent, effectively allocating slice resources, and consistently maintaining optimal performance.
A Federated Online Restless Bandit Framework for Cooperative Resource Allocation
Jun 12, 2024Restless multi-armed bandits (RMABs) have been widely utilized to address resource allocation problems with Markov reward processes (MRPs). Existing works often assume that the dynamics of MRPs are known prior, which makes the RMAB problem solvable from an optimization perspective. Nevertheless, an efficient learning-based solution for RMABs with unknown system dynamics remains an open problem. In this paper, we study the cooperative resource allocation problem with unknown system dynamics of MRPs. This problem can be modeled as a multi-agent online RMAB problem, where multiple agents collaboratively learn the system dynamics while maximizing their accumulated rewards. We devise a federated online RMAB framework to mitigate the communication overhead and data privacy issue by adopting the federated learning paradigm. Based on this framework, we put forth a Federated Thompson Sampling-enabled Whittle Index (FedTSWI) algorithm to solve this multi-agent online RMAB problem. The FedTSWI algorithm enjoys a high communication and computation efficiency, and a privacy guarantee. Moreover, we derive a regret upper bound for the FedTSWI algorithm. Finally, we demonstrate the effectiveness of the proposed algorithm on the case of online multi-user multi-channel access. Numerical results show that the proposed algorithm achieves a fast convergence rate of $\mathcal{O}(\sqrt{T\log(T)})$ and better performance compared with baselines. More importantly, its sample complexity decreases with the number of agents.
Two-Stage Resource Allocation in Reconfigurable Intelligent Surface Assisted Hybrid Networks via Multi-Player Bandits
Jun 09, 2024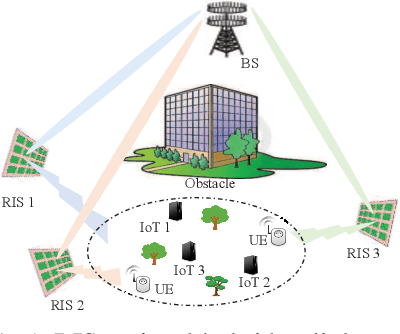
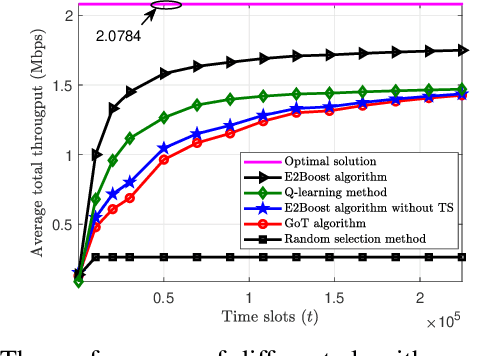
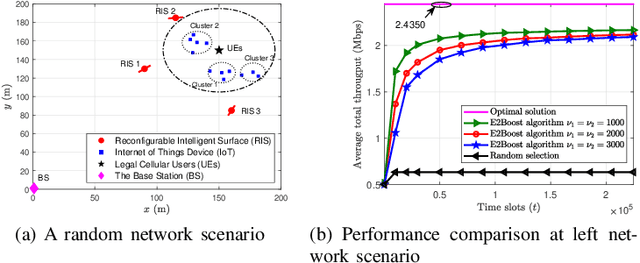
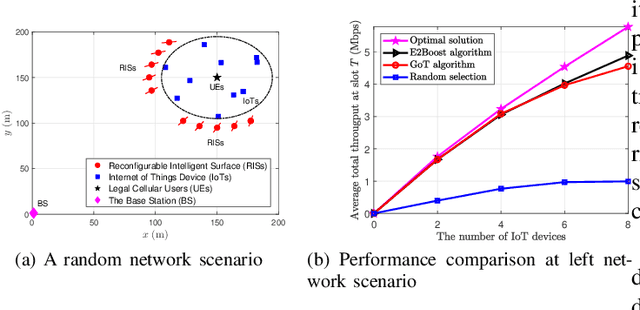
This paper considers a resource allocation problem where several Internet-of-Things (IoT) devices send data to a base station (BS) with or without the help of the reconfigurable intelligent surface (RIS) assisted cellular network. The objective is to maximize the sum rate of all IoT devices by finding the optimal RIS and spreading factor (SF) for each device. Since these IoT devices lack prior information on the RISs or the channel state information (CSI), a distributed resource allocation framework with low complexity and learning features is required to achieve this goal. Therefore, we model this problem as a two-stage multi-player multi-armed bandit (MPMAB) framework to learn the optimal RIS and SF sequentially. Then, we put forth an exploration and exploitation boosting (E2Boost) algorithm to solve this two-stage MPMAB problem by combining the $\epsilon$-greedy algorithm, Thompson sampling (TS) algorithm, and non-cooperation game method. We derive an upper regret bound for the proposed algorithm, i.e., $\mathcal{O}(\log^{1+\delta}_2 T)$, increasing logarithmically with the time horizon $T$. Numerical results show that the E2Boost algorithm has the best performance among the existing methods and exhibits a fast convergence rate. More importantly, the proposed algorithm is not sensitive to the number of combinations of the RISs and SFs thanks to the two-stage allocation mechanism, which can benefit high-density networks.
WirelessLLM: Empowering Large Language Models Towards Wireless Intelligence
May 27, 2024



The rapid evolution of wireless technologies and the growing complexity of network infrastructures necessitate a paradigm shift in how communication networks are designed, configured, and managed. Recent advancements in Large Language Models (LLMs) have sparked interest in their potential to revolutionize wireless communication systems. However, existing studies on LLMs for wireless systems are limited to a direct application for telecom language understanding. To empower LLMs with knowledge and expertise in the wireless domain, this paper proposes WirelessLLM, a comprehensive framework for adapting and enhancing LLMs to address the unique challenges and requirements of wireless communication networks. We first identify three foundational principles that underpin WirelessLLM: knowledge alignment, knowledge fusion, and knowledge evolution. Then, we investigate the enabling technologies to build WirelessLLM, including prompt engineering, retrieval augmented generation, tool usage, multi-modal pre-training, and domain-specific fine-tuning. Moreover, we present three case studies to demonstrate the practical applicability and benefits of WirelessLLM for solving typical problems in wireless networks. Finally, we conclude this paper by highlighting key challenges and outlining potential avenues for future research.