 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessing Higher Dimensions for Unsupervised Word Translation
Paper and Code
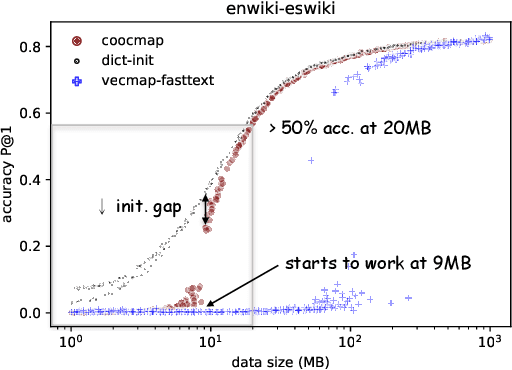
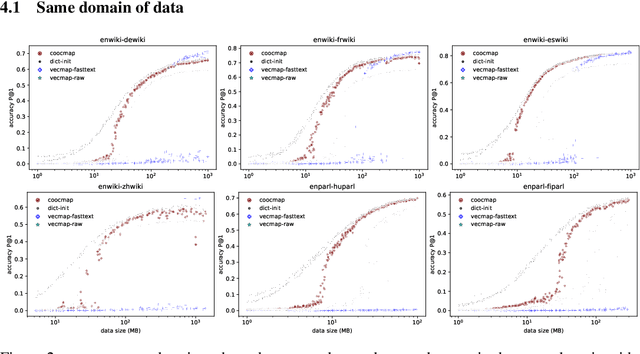
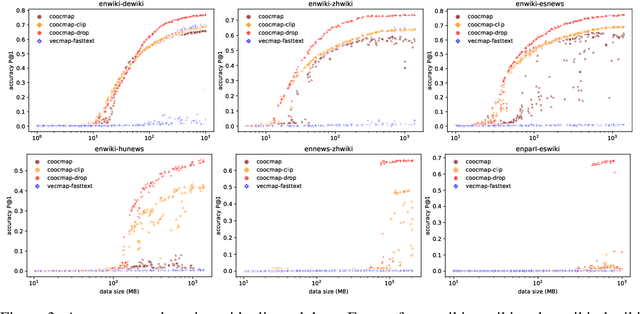
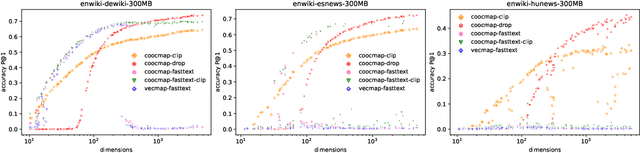
The striking ability of unsupervised word translation has been demonstrated with the help of word vectors / pretraining; however, they require large amounts of data and usually fails if the data come from different domains. We propose coocmap, a method that can use either high-dimensional co-occurrence counts or their lower-dimensional approximations. Freed from the limits of low dimensions, we show that relying on low-dimensional vectors and their incidental properties miss out on better denoising methods and useful world knowledge in high dimensions, thus stunting the potential of the data. Our results show that unsupervised translation can be achieved more easily and robustly than previously thought -- less than 80MB and minutes of CPU time is required to achieve over 50\% accuracy for English to Finnish, Hungarian, and Chinese translations when trained on similar data; even under domain mismatch, we show coocmap still works fully unsupervised on English NewsCrawl to Chinese Wikipedia and English Europarl to Spanish Wikipedia, among others. These results challenge prevailing assumptions on the necessity and superiority of low-dimensional vectors, and suggest that similarly processed co-occurrences can outperform dense vectors on other tasks too.