 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitextEdit: Automatic Bitext Editing for Improved Low-Resource Machine Translation
Paper and Code
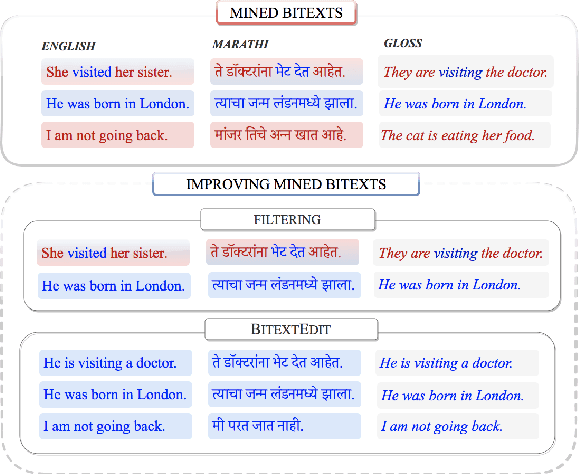
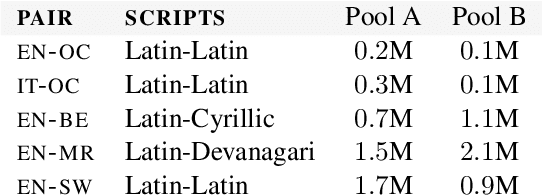
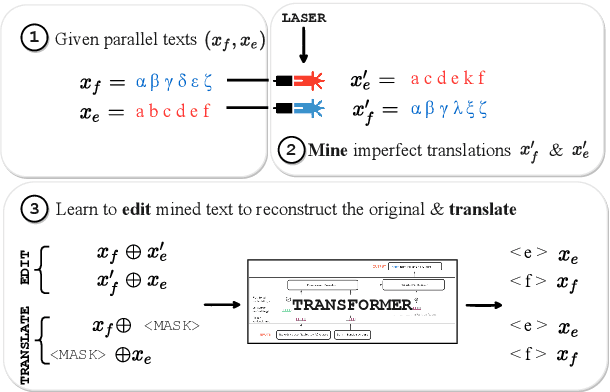
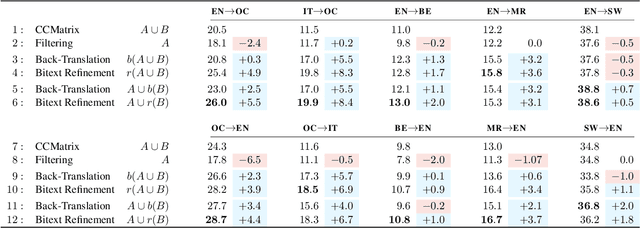
Mined bitexts can contain imperfect translations that yield unreliable training signals for Neural Machine Translation (NMT). While filtering such pairs out is known to improve final model quality, we argue that it is suboptimal in low-resource conditions where even mined data can be limited. In our work, we propose instead, to refine the mined bitexts via automatic editing: given a sentence in a language xf, and a possibly imperfect translation of it xe, our model generates a revised version xf' or xe' that yields a more equivalent translation pair (i.e., <xf, xe'> or <xf', xe>). We use a simple editing strategy by (1) mining potentially imperfect translations for each sentence in a given bitext, (2) learning a model to reconstruct the original translations and translate, in a multi-task fashion. Experiments demonstrate that our approach successfully improves the quality of CCMatrix mined bitext for 5 low-resource language-pairs and 10 translation directions by up to ~ 8 BLEU points, in most cases improving upon a competitive back-translation baseline.