 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSILG: The Multi-environment Symbolic Interactive Language Grounding Benchmark
Paper and Code
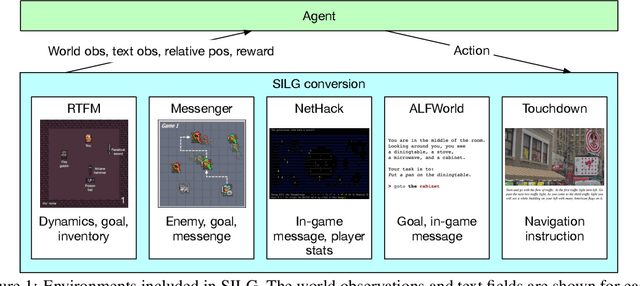
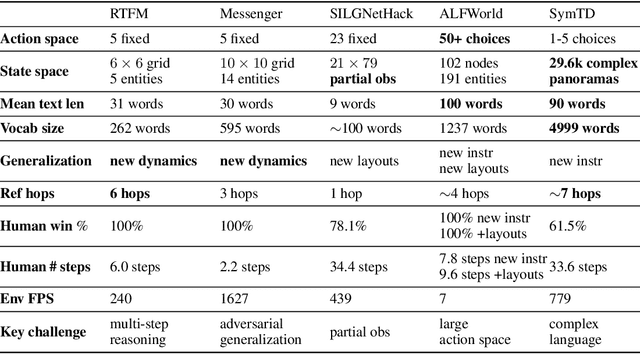
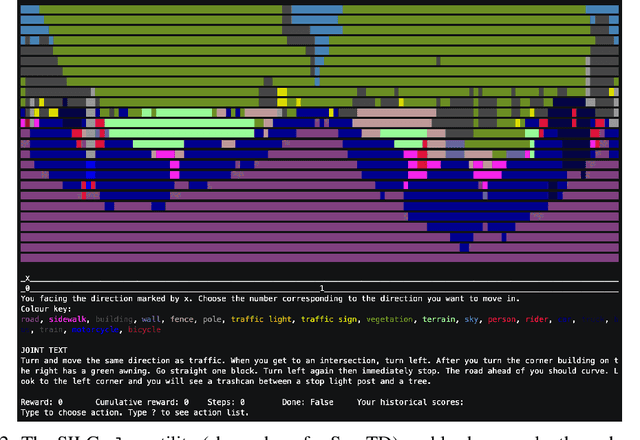
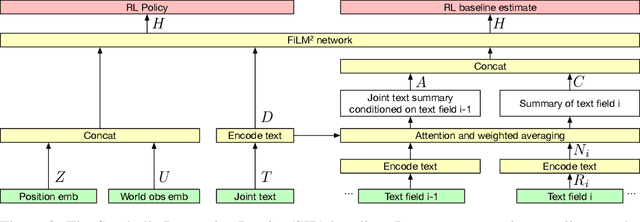
Existing work in language grounding typically study single environments. How do we build unified models that apply across multiple environments? We propose the multi-environment Symbolic Interactive Language Grounding benchmark (SILG), which unifies a collection of diverse grounded language learning environments under a common interface. SILG consists of grid-world environments that require generalization to new dynamics, entities, and partially observed worlds (RTFM, Messenger, NetHack), as well as symbolic counterparts of visual worlds that require interpreting rich natural language with respect to complex scenes (ALFWorld, Touchdown). Together, these environments provide diverse grounding challenges in richness of observation space, action space, language specification, and plan complexity. In addition, we propose the first shared model architecture for RL on these environments, and evaluate recent advances such as egocentric local convolution, recurrent state-tracking, entity-centric attention, and pretrained LM using SILG. Our shared architecture achieves comparable performance to environment-specific architectures. Moreover, we find that many recent modelling advances do not result in significant gains on environments other than the one they were designed for. This highlights the need for a multi-environment benchmark. Finally, the best models significantly underperform humans on SILG, which suggests ample room for future work. We hope SILG enables the community to quickly identify new methodologies for language grounding that generalize to a diverse set of environments and their associated challenges.