 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributing Culture-Conditioned Generations to Pretraining Corpora
Dec 30, 2024



In open-ended generative tasks like narrative writing or dialogue, large language models often exhibit cultural biases, showing limited knowledge and generating templated outputs for less prevalent cultures. Recent works show that these biases may stem from uneven cultural representation in pretraining corpora. This work investigates how pretraining leads to biased culture-conditioned generations by analyzing how models associate entities with cultures based on pretraining data patterns. We propose the MEMOed framework (MEMOrization from pretraining document) to determine whether a generation for a culture arises from memorization. Using MEMOed on culture-conditioned generations about food and clothing for 110 cultures, we find that high-frequency cultures in pretraining data yield more generations with memorized symbols, while some low-frequency cultures produce none. Additionally, the model favors generating entities with extraordinarily high frequency regardless of the conditioned culture, reflecting biases toward frequent pretraining terms irrespective of relevance. We hope that the MEMOed framework and our insights will inspire more works on attributing model performance on pretraining data.
CULTURE-GEN: Revealing Global Cultural Perception in Language Models through Natural Language Prompting
Apr 16, 2024As the utilization of large language models (LLMs) has proliferated worldwide, it is crucial for them to have adequate knowledge and fair representation for diverse global cultures. In this work, we uncover culture perceptions of three SOTA models on 110 countries and regions on 8 culture-related topics through culture-conditioned generations, and extract symbols from these generations that are associated to each culture by the LLM. We discover that culture-conditioned generation consist of linguistic "markers" that distinguish marginalized cultures apart from default cultures. We also discover that LLMs have an uneven degree of diversity in the culture symbols, and that cultures from different geographic regions have different presence in LLMs' culture-agnostic generation. Our findings promote further research in studying the knowledge and fairness of global culture perception in LLMs. Code and Data can be found in: https://github.com/huihanlhh/Culture-Gen/
In Search of the Long-Tail: Systematic Generation of Long-Tail Knowledge via Logical Rule Guided Search
Nov 13, 2023



Since large language models have approached human-level performance on many tasks, it has become increasingly harder for researchers to find tasks that are still challenging to the models. Failure cases usually come from the long-tail distribution - data that an oracle language model could assign a probability on the lower end of its distribution. Current methodology such as prompt engineering or crowdsourcing are insufficient for creating long-tail examples because humans are constrained by cognitive bias. We propose a Logic-Induced-Knowledge-Search (LINK) framework for systematically generating long-tail knowledge statements. Grounded by a symbolic rule, we search for long-tail values for each variable of the rule by first prompting a LLM, then verifying the correctness of the values with a critic, and lastly pushing for the long-tail distribution with a reranker. With this framework we construct a dataset, Logic-Induced-Long-Tail (LINT), consisting of 200 symbolic rules and 50K knowledge statements spanning across four domains. Human annotations find that 84% of the statements in LINT are factually correct. In contrast, ChatGPT and GPT4 struggle with directly generating long-tail statements under the guidance of logic rules, each only getting 56% and 78% of their statements correct. Moreover, their "long-tail" generations in fact fall into the higher likelihood range, and thus are not really long-tail. Our findings suggest that LINK is effective for generating data in the long-tail distribution while enforcing quality. LINT can be useful for systematically evaluating LLMs' capabilities in the long-tail distribution. We challenge the models with a simple entailment classification task using samples from LINT. We find that ChatGPT and GPT4's capability in identifying incorrect knowledge drop by ~3% in the long-tail distribution compared to head distribution.
Controllable Text Generation with Language Constraints
Dec 20, 2022



We consider the task of text generation in language models with constraints specified in natural language. To this end, we first create a challenging benchmark Cognac that provides as input to the model a topic with example text, along with a constraint on text to be avoided. Unlike prior work, our benchmark contains knowledge-intensive constraints sourced from databases like Wordnet and Wikidata, which allows for straightforward evaluation while striking a balance between broad attribute-level and narrow lexical-level controls. We find that even state-of-the-art language models like GPT-3 fail often on this task, and propose a solution to leverage a language model's own internal knowledge to guide generation. Our method, called CognacGen, first queries the language model to generate guidance terms for a specified topic or constraint, and uses the guidance to modify the model's token generation probabilities. We propose three forms of guidance (binary verifier, top-k tokens, textual example), and employ prefix-tuning approaches to distill the guidance to tackle diverse natural language constraints. Through extensive empirical evaluations, we demonstrate that CognacGen can successfully generalize to unseen instructions and outperform competitive baselines in generating constraint conforming text.
Ditch the Gold Standard: Re-evaluating Conversational Question Answering
Dec 16, 2021

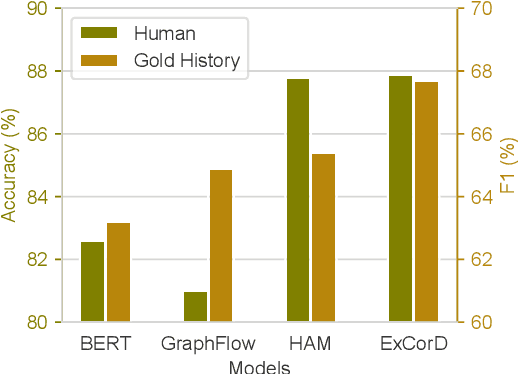
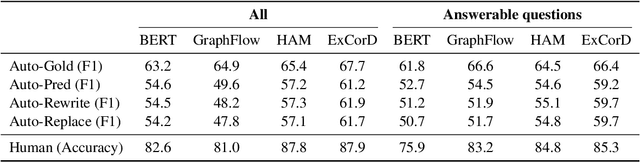
Conversational question answering (CQA) systems aim to provide natural-language answers to users in information-seeking conversations. Existing CQA benchmarks compare models with pre-collected human-human conversations, using ground-truth answers provided in conversational history. It remains unclear whether we can rely on this static evaluation for model development and whether current systems can well generalize to real-world human-machine conversations. In this work, we conduct the first large-scale human evaluation of state-of-the-art CQA systems, where human evaluators converse with models and judge the correctness of their answers. We find that the distribution of human-machine conversations differs drastically from that of human-human conversations, and there is a disagreement between human and gold-history evaluation in terms of model ranking. We further investigate how to improve automatic evaluations, and propose a question rewriting mechanism based on predicted history, which better correlates with human judgments. Finally, we discuss the impact of various modeling strategies and future directions towards better conversational question answering systems.