 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoIOT: LLM-Driven Automated Natural Language Programming for AIoT Applications
Mar 07, 2025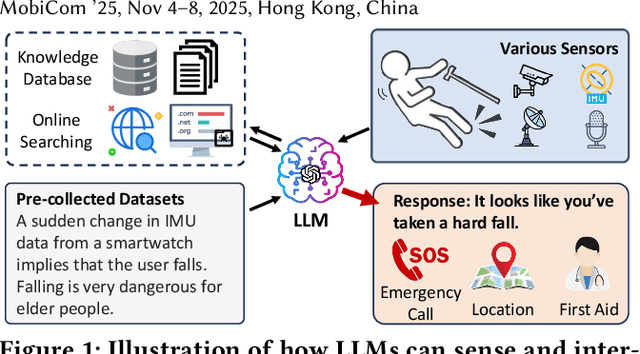


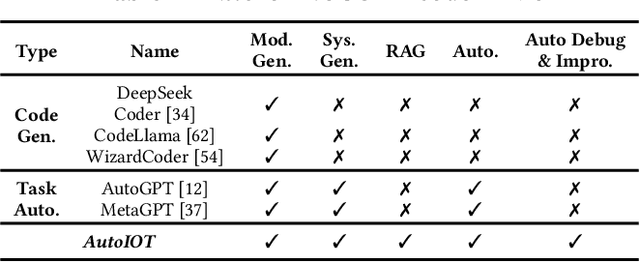
The advent of Large Language Models (LLMs) has profoundly transformed our lives, revolutionizing interactions with AI and lowering the barrier to AI usage. While LLMs are primarily designed for natural language interaction, the extensive embedded knowledge empowers them to comprehend digital sensor data. This capability enables LLMs to engage with the physical world through IoT sensors and actuators, performing a myriad of AIoT tasks. Consequently, this evolution triggers a paradigm shift in conventional AIoT application development, democratizing its accessibility to all by facilitating the design and development of AIoT applications via natural language. However, some limitations need to be addressed to unlock the full potential of LLMs in AIoT application development. First, existing solutions often require transferring raw sensor data to LLM servers, which raises privacy concerns, incurs high query fees, and is limited by token size. Moreover, the reasoning processes of LLMs are opaque to users, making it difficult to verify the robustness and correctness of inference results. This paper introduces AutoIOT, an LLM-based automated program generator for AIoT applications. AutoIOT enables users to specify their requirements using natural language (input) and automatically synthesizes interpretable programs with documentation (output). AutoIOT automates the iterative optimization to enhance the quality of generated code with minimum user involvement. AutoIOT not only makes the execution of AIoT tasks more explainable but also mitigates privacy concerns and reduces token costs with local execution of synthesized programs. Extensive experiments and user studies demonstrate AutoIOT's remarkable capability in program synthesis for various AIoT tasks. The synthesized programs can match and even outperform some representative baselines.
FedConv: A Learning-on-Model Paradigm for Heterogeneous Federated Clients
Feb 28, 2025



Federated Learning (FL) facilitates collaborative training of a shared global model without exposing clients' private data. In practical FL systems, clients (e.g., edge servers, smartphones, and wearables) typically have disparate system resources. Conventional FL, however, adopts a one-size-fits-all solution, where a homogeneous large global model is transmitted to and trained on each client, resulting in an overwhelming workload for less capable clients and starvation for other clients. To address this issue, we propose FedConv, a client-friendly FL framework, which minimizes the computation and memory burden on resource-constrained clients by providing heterogeneous customized sub-models. FedConv features a novel learning-on-model paradigm that learns the parameters of the heterogeneous sub-models via convolutional compression. Unlike traditional compression methods, the compressed models in FedConv can be directly trained on clients without decompression. To aggregate the heterogeneous sub-models, we propose transposed convolutional dilation to convert them back to large models with a unified size while retaining personalized information from clients. The compression and dilation processes, transparent to clients, are optimized on the server leveraging a small public dataset. Extensive experiments on six datasets demonstrate that FedConv outperforms state-of-the-art FL systems in terms of model accuracy (by more than 35% on average), computation and communication overhead (with 33% and 25% reduction, respectively).