 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXRF V2: A Dataset for Action Summarization with Wi-Fi Signals, and IMUs in Phones, Watches, Earbuds, and Glasses
Jan 31, 2025



Human Action Recognition (HAR) plays a crucial role in applications such as health monitoring, smart home automation, and human-computer interaction. While HAR has been extensively studied, action summarization, which involves identifying and summarizing continuous actions, remains an emerging task. This paper introduces the novel XRF V2 dataset, designed for indoor daily activity Temporal Action Localization (TAL) and action summarization. XRF V2 integrates multimodal data from Wi-Fi signals, IMU sensors (smartphones, smartwatches, headphones, and smart glasses), and synchronized video recordings, offering a diverse collection of indoor activities from 16 volunteers across three distinct environments. To tackle TAL and action summarization, we propose the XRFMamba neural network, which excels at capturing long-term dependencies in untrimmed sensory sequences and outperforms state-of-the-art methods, such as ActionFormer and WiFiTAD. We envision XRF V2 as a valuable resource for advancing research in human action localization, action forecasting, pose estimation, multimodal foundation models pre-training, synthetic data generation, and more.
EgoHand: Ego-centric Hand Pose Estimation and Gesture Recognition with Head-mounted Millimeter-wave Radar and IMUs
Jan 23, 2025



Recent advanced Virtual Reality (VR) headsets, such as the Apple Vision Pro, employ bottom-facing cameras to detect hand gestures and inputs, which offers users significant convenience in VR interactions. However, these bottom-facing cameras can sometimes be inconvenient and pose a risk of unintentionally exposing sensitive information, such as private body parts or personal surroundings. To mitigate these issues, we introduce EgoHand. This system provides an alternative solution by integrating millimeter-wave radar and IMUs for hand gesture recognition, thereby offering users an additional option for gesture interaction that enhances privacy protection. To accurately recognize hand gestures, we devise a two-stage skeleton-based gesture recognition scheme. In the first stage, a novel end-to-end Transformer architecture is employed to estimate the coordinates of hand joints. Subsequently, these estimated joint coordinates are utilized for gesture recognition. Extensive experiments involving 10 subjects show that EgoHand can detect hand gestures with 90.8% accuracy. Furthermore, EgoHand demonstrates robust performance across a variety of cross-domain tests, including different users, dominant hands, body postures, and scenes.
Temporal Unet: Sample Level Human Action Recognition using WiFi
Apr 19, 2019


Human doing actions will result in WiFi distortion, which is widely explored for action recognition, such as the elderly fallen detection, hand sign language recognition, and keystroke estimation. As our best survey, past work recognizes human action by categorizing one complete distortion series into one action, which we term as series-level action recognition. In this paper, we introduce a much more fine-grained and challenging action recognition task into WiFi sensing domain, i.e., sample-level action recognition. In this task, every WiFi distortion sample in the whole series should be categorized into one action, which is a critical technique in precise action localization, continuous action segmentation, and real-time action recognition. To achieve WiFi-based sample-level action recognition, we fully analyze approaches in image-based semantic segmentation as well as in video-based frame-level action recognition, then propose a simple yet efficient deep convolutional neural network, i.e., Temporal Unet. Experimental results show that Temporal Unet achieves this novel task well. Codes have been made publicly available at https://github.com/geekfeiw/WiSLAR.
Human activity recognition based on time series analysis using U-Net
Sep 20, 2018


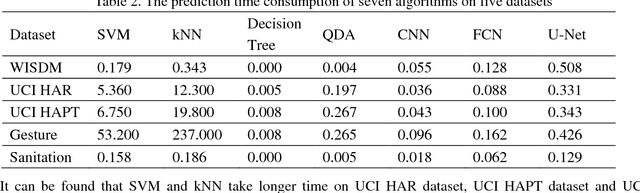
Traditional human activity recognition (HAR) based on time series adopts sliding window analysis method. This method faces the multi-class window problem which mistakenly labels different classes of sampling points within a window as a class. In this paper, a HAR algorithm based on U-Net is proposed to perform activity labeling and prediction at each sampling point. The activity data of the triaxial accelerometer is mapped into an image with the single pixel column and multi-channel which is input into the U-Net network for training and recognition. Our proposal can complete the pixel-level gesture recognition function. The method does not need manual feature extraction and can effectively identify short-term behaviors in long-term activity sequences. We collected the Sanitation dataset and tested the proposed scheme with four open data sets. The experimental results show that compared with Support Vector Machine (SVM), k-Nearest Neighbor (kNN), Decision Tree(DT), Quadratic Discriminant Analysis (QDA), Convolutional Neural Network (CNN) and Fully Convolutional Networks (FCN) methods, our proposal has the highest accuracy and F1-socre in each dataset, and has stable performance and high robustness. At the same time, after the U-Net has finished training, our proposal can achieve fast enough recognition speed.