 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning with Fully Convolutional Networks
Paper and Code
Dec 18, 2020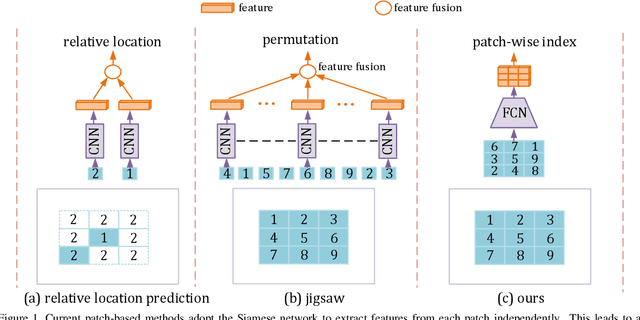
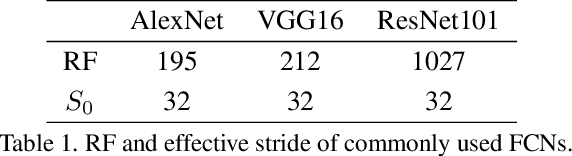
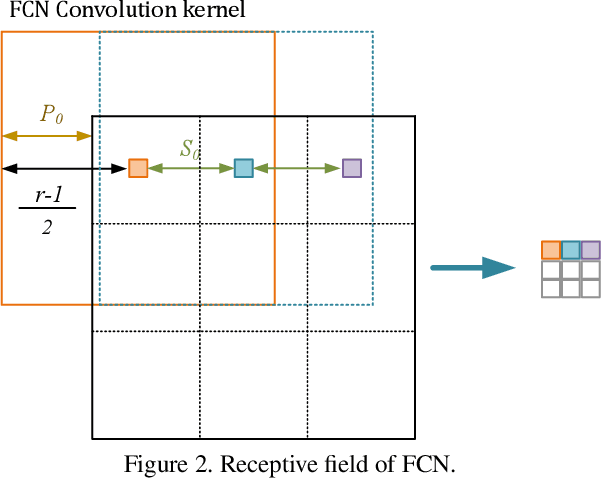

Although deep learning based methods have achieved great success in many computer vision tasks, their performance relies on a large number of densely annotated samples that are typically difficult to obtain. In this paper, we focus on the problem of learning representation from unlabeled data for semantic segmentation. Inspired by two patch-based methods, we develop a novel self-supervised learning framework by formulating the Jigsaw Puzzle problem as a patch-wise classification process and solving it with a fully convolutional network. By learning to solve a Jigsaw Puzzle problem with 25 patches and transferring the learned features to semantic segmentation task on Cityscapes dataset, we achieve a 5.8 percentage point improvement over the baseline model that initialized from random values. Moreover, experiments show that our self-supervised learning method can be applied to different datasets and models. In particular, we achieved competitive performance with the state-of-the-art methods on the PASCAL VOC2012 dataset using significant fewer training images.