 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Full Label: Single-Point Prompt for Infrared Small Target Label Generation
Aug 15, 2024



In this work, we make the first attempt to construct a learning-based single-point annotation paradigm for infrared small target label generation (IRSTLG). Our intuition is that label generation requires just one more point prompt than target detection: IRSTLG can be regarded as an infrared small target detection (IRSTD) task with the target location hint. Based on this insight, we introduce an energy double guided single-point prompt (EDGSP) framework, which adeptly transforms the target detection network into a refined label generation method. Specifically, the proposed EDGSP includes: 1) target energy initialization (TEI) to create a foundational outline for sufficient shape evolution of pseudo label, 2) double prompt embedding (DPE) for rapid localization of interested regions and reinforcement of individual differences to avoid label adhesion, and 3) bounding box-based matching (BBM) to eliminate false alarms. Experimental results show that pseudo labels generated by three baselines equipped with EDGSP achieve 100% object-level probability of detection (Pd) and 0% false-alarm rate (Fa) on SIRST, NUDT-SIRST, and IRSTD-1k datasets, with a pixel-level intersection over union (IoU) improvement of 13.28% over state-of-the-art label generation methods. Additionally, the downstream detection task reveals that our centroid-annotated pseudo labels surpass full labels, even with coarse single-point annotations, it still achieves 99.5% performance of full labeling.
DestripeCycleGAN: Stripe Simulation CycleGAN for Unsupervised Infrared Image Destriping
Feb 14, 2024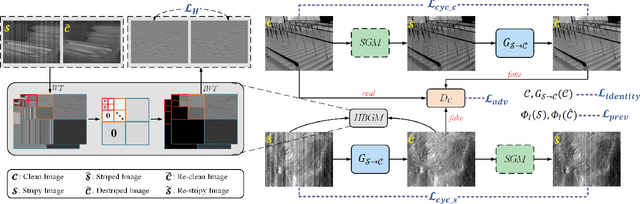
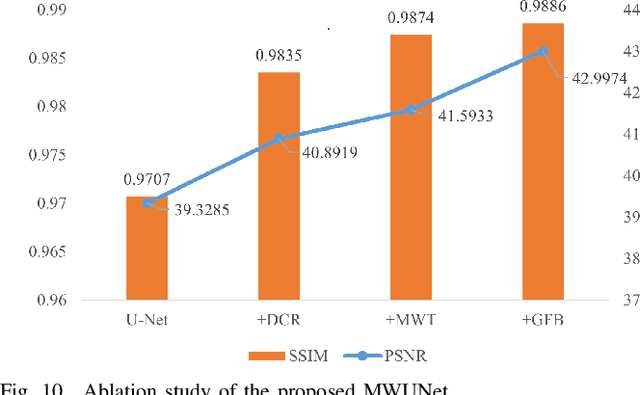

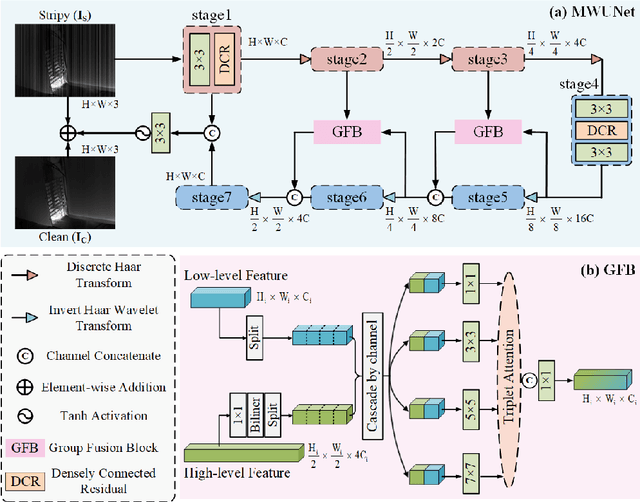
CycleGAN has been proven to be an advanced approach for unsupervised image restoration. This framework consists of two generators: a denoising one for inference and an auxiliary one for modeling noise to fulfill cycle-consistency constraints. However, when applied to the infrared destriping task, it becomes challenging for the vanilla auxiliary generator to consistently produce vertical noise under unsupervised constraints. This poses a threat to the effectiveness of the cycle-consistency loss, leading to stripe noise residual in the denoised image. To address the above issue, we present a novel framework for single-frame infrared image destriping, named DestripeCycleGAN. In this model, the conventional auxiliary generator is replaced with a priori stripe generation model (SGM) to introduce vertical stripe noise in the clean data, and the gradient map is employed to re-establish cycle-consistency. Meanwhile, a Haar wavelet background guidance module (HBGM) has been designed to minimize the divergence of background details between the different domains. To preserve vertical edges, a multi-level wavelet U-Net (MWUNet) is proposed as the denoising generator, which utilizes the Haar wavelet transform as the sampler to decline directional information loss. Moreover, it incorporates the group fusion block (GFB) into skip connections to fuse the multi-scale features and build the context of long-distance dependencies. Extensive experiments on real and synthetic data demonstrate that our DestripeCycleGAN surpasses the state-of-the-art methods in terms of visual quality and quantitative evaluation. Our code will be made public at https://github.com/0wuji/DestripeCycleGAN.
SCTransNet: Spatial-channel Cross Transformer Network for Infrared Small Target Detection
Feb 01, 2024



Infrared small target detection (IRSTD) has recently benefitted greatly from U-shaped neural models. However, largely overlooking effective global information modeling, existing techniques struggle when the target has high similarities with the background. We present a Spatial-channel Cross Transformer Network (SCTransNet) that leverages spatial-channel cross transformer blocks (SCTBs) on top of long-range skip connections to address the aforementioned challenge. In the proposed SCTBs, the outputs of all encoders are interacted with cross transformer to generate mixed features, which are redistributed to all decoders to effectively reinforce semantic differences between the target and clutter at full scales. Specifically, SCTB contains the following two key elements: (a) spatial-embedded single-head channel-cross attention (SSCA) for exchanging local spatial features and full-level global channel information to eliminate ambiguity among the encoders and facilitate high-level semantic associations of the images, and (b) a complementary feed-forward network (CFN) for enhancing the feature discriminability via a multi-scale strategy and cross-spatial-channel information interaction to promote beneficial information transfer. Our SCTransNet effectively encodes the semantic differences between targets and backgrounds to boost its internal representation for detecting small infrared targets accurately. Extensive experiments on three public datasets, NUDT-SIRST, NUAA-SIRST, and IRSTD-1k, demonstrate that the proposed SCTransNet outperforms existing IRSTD methods. Our code will be made public at https://github.com/xdFai.
ARCNet: An Asymmetric Residual Wavelet Column Correction Network for Infrared Image Destriping
Jan 28, 2024



Infrared image destriping seeks to restore high-quality content from degraded images. Recent works mainly address this task by leveraging prior knowledge to separate stripe noise from the degraded image. However, constructing a robust decoupling model for that purpose remains challenging, especially when significant similarities exist between the stripe noise and vertical background structure. Addressing that, we introduce Asymmetric Residual wavelet Column correction Network (ARCNet) for image destriping, aiming to consistently preserve spatially precise high-resolution representations. Our neural model leverages a novel downsampler, residual haar discrete wavelet transform (RHDWT), stripe directional prior knowledge and data-driven learning to induce a model with enriched feature representation of stripe noise and background. In our technique, the inverse wavelet transform is replaced by transposed convolution for feature upsampling, which can suppress noise crosstalk and encourage the network to focus on robust image reconstruction. After each sampling, a proposed column non-uniformity correction module (CNCM) is leveraged by our method to enhance column uniformity, spatial correlation, and global self-dependence between each layer component. CNCM can establish structural characteristics of stripe noise and utilize contextual information at long-range dependencies to distinguish stripes with varying intensities and distributions. Extensive experiments on synthetic data, real data, and infrared small target detection tasks show that the proposed method outperforms state-of-the-art single-image destriping methods both visually and quantitatively by a considerable margin. Our code will be made publicly available at \url{https://github.com/xdFai}.
Unsupervised Deep Multi-focus Image Fusion
Jun 19, 2018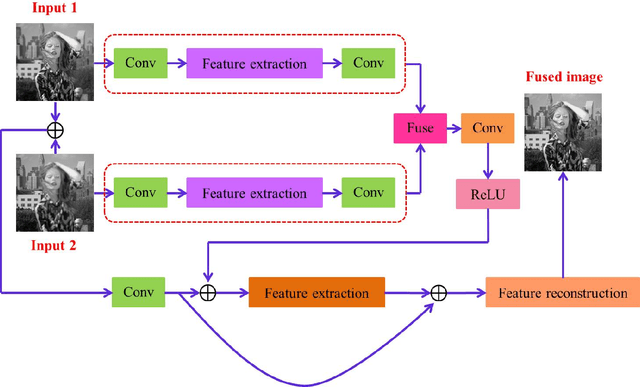

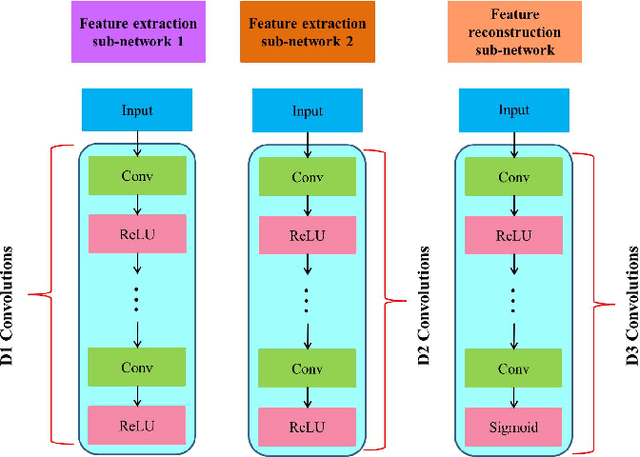

Convolutional neural networks have recently been used for multi-focus image fusion. However, due to the lack of labeled data for supervised training of such networks, existing methods have resorted to adding Gaussian blur in focused images to simulate defocus and generate synthetic training data with ground-truth for supervised learning. Moreover, they classify pixels as focused or defocused and leverage the results to construct the fusion weight maps which then necessitates a series of post-processing steps. In this paper, we present unsupervised end-to-end learning for directly predicting the fully focused output image from multi-focus input image pairs. The proposed approach uses a novel CNN architecture trained to perform fusion without the need for ground truth fused images and exploits the image structural similarity (SSIM) to calculate the loss; a metric that is widely accepted for fused image quality evaluation. Consequently, we are able to utilize {\em real} benchmark datasets, instead of simulated ones, to train our network. The model is a feed-forward, fully convolutional neural network that can process images of variable sizes during test time. Extensive evaluations on benchmark datasets show that our method outperforms existing state-of-the-art in terms of visual quality and objective evaluations.
Deep Keyframe Detection in Human Action Videos
Apr 26, 2018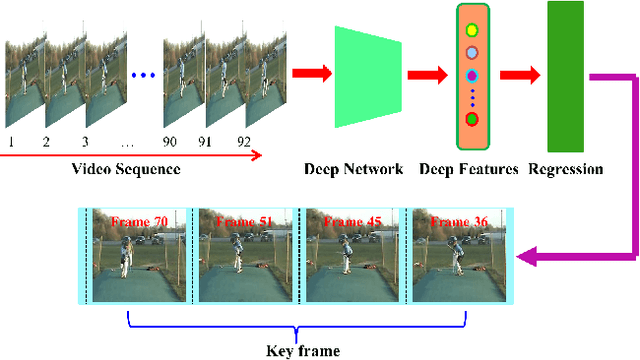
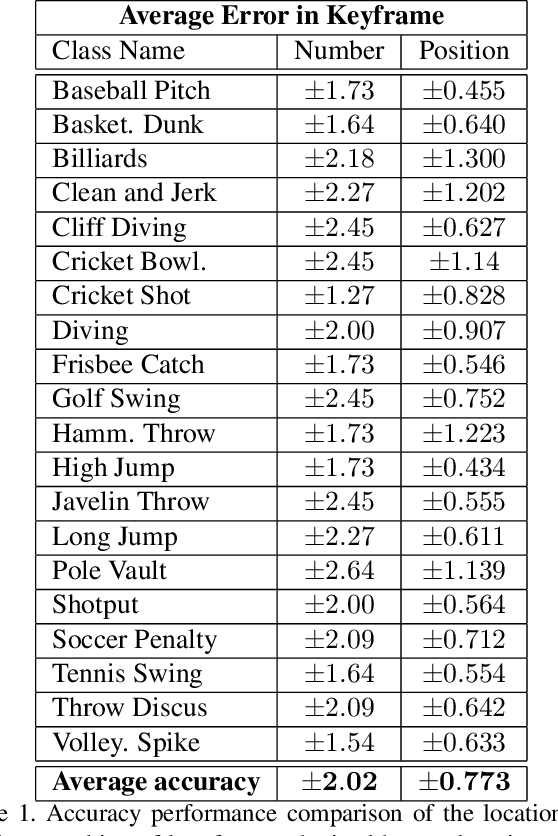


Detecting representative frames in videos based on human actions is quite challenging because of the combined factors of human pose in action and the background. This paper addresses this problem and formulates the key frame detection as one of finding the video frames that optimally maximally contribute to differentiating the underlying action category from all other categories. To this end, we introduce a deep two-stream ConvNet for key frame detection in videos that learns to directly predict the location of key frames. Our key idea is to automatically generate labeled data for the CNN learning using a supervised linear discriminant method. While the training data is generated taking many different human action videos into account, the trained CNN can predict the importance of frames from a single video. We specify a new ConvNet framework, consisting of a summarizer and discriminator. The summarizer is a two-stream ConvNet aimed at, first, capturing the appearance and motion features of video frames, and then encoding the obtained appearance and motion features for video representation. The discriminator is a fitting function aimed at distinguishing between the key frames and others in the video. We conduct experiments on a challenging human action dataset UCF101 and show that our method can detect key frames with high accuracy.