 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating a Benchmark for Training-set free Evaluation of Linguistic Capabilities in Machine Reading Comprehension
Paper and Code
Aug 09, 2024
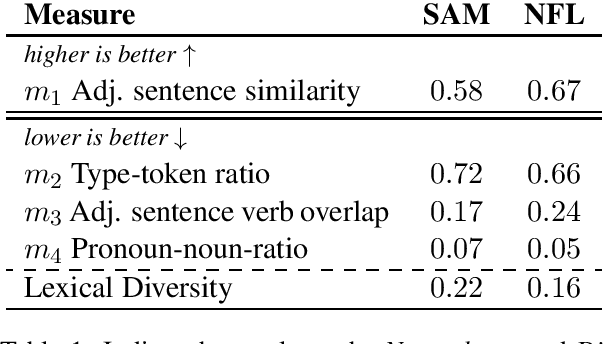
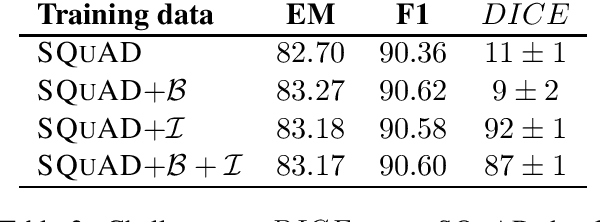

Performance of NLP systems is typically evaluated by collecting a large-scale dataset by means of crowd-sourcing to train a data-driven model and evaluate it on a held-out portion of the data. This approach has been shown to suffer from spurious correlations and the lack of challenging examples that represent the diversity of natural language. Instead, we examine a framework for evaluating optimised models in training-set free setting on synthetically generated challenge sets. We find that despite the simplicity of the generation method, the data can compete with crowd-sourced datasets with regard to naturalness and lexical diversity for the purpose of evaluating the linguistic capabilities of MRC models. We conduct further experiments and show that state-of-the-art language model-based MRC systems can learn to succeed on the challenge set correctly, although, without capturing the general notion of the evaluated phenomenon.