 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressive Fourier-Domain Intensity Coupling (C-FOCUS) enables near-millimeter deep imaging in the intact mouse brain in vivo
May 27, 2025Two-photon microscopy is a powerful tool for in vivo imaging, but its imaging depth is typically limited to a few hundred microns due to tissue scattering, even with existing scattering correction techniques. Moreover, most active scattering correction methods are restricted to small regions by the optical memory effect. Here, we introduce compressive Fourier-domain intensity coupling for scattering correction (C-FOCUS), an active scattering correction approach that integrates Fourier-domain intensity modulation with compressive sensing for two-photon microscopy. Using C-FOCUS, we demonstrate high-resolution imaging of YFP-labeled neurons and FITC-labeled blood vessels at depths exceeding 900 um in the intact mouse brain in vivo. Furthermore, we achieve transcranial imaging of YFP-labeled dendritic structures through the intact adult mouse skull. C-FOCUS enables high-contrast fluorescence imaging at depths previously inaccessible using two-photon microscopy with 1035 nm excitation, enhancing fluorescence intensity by over 20-fold compared to uncorrected imaging. C-FOCUS provides a broadly applicable strategy for rapid, deep-tissue optical imaging in vivo.
Fluorescence Diffraction Tomography using Explicit Neural Fields
Jul 23, 2024



Solving the 3D refractive index (RI) from fluorescence images provides both fluorescence and phase information about biological samples. However, accurately retrieving the phase of partially coherent light to reconstruct the unknown RI of label-free phase objects over a large volume, at high resolution, and in reflection mode remains challenging. To tackle this challenge, we developed fluorescence diffraction tomography (FDT) with explicit neural fields that can reconstruct 3D RI from defocused fluorescence speckle images. The successful reconstruction of 3D RI using FDT relies on four key components: coarse-to-fine modeling, self-calibration, a differential multi-slice rendering model, and partial coherent masks. Specifically, the explicit representation efficiently integrates with the coarse-to-fine modeling to achieve high-speed, high-resolution reconstruction. Moreover, we advance the multi-slice equation to differential multi-slice rendering model, which enables the self-calibration method for the extrinsic and intrinsic parameters of the system. The self-calibration facilitates high accuracy forward image prediction and RI reconstruction. Partial coherent masks are digital masks to resolve the discrepancies between the coherent light model and the partial coherent light data accurately and efficiently. FDT successfully reconstructed the RI of 3D cultured label-free 3D MuSCs tube in a 530 $\times$ 530 $\times$ 300 $\mu m^3$ volume at 1024$\times$1024 pixels across 24 $z$-layers from fluorescence images, demonstrating high fidelity 3D RI reconstruction of bulky and heterogeneous biological samples in vitro.
Multi-task Learning for Monocular Depth and Defocus Estimations with Real Images
Aug 21, 2022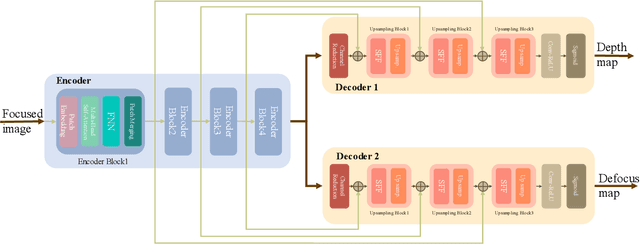
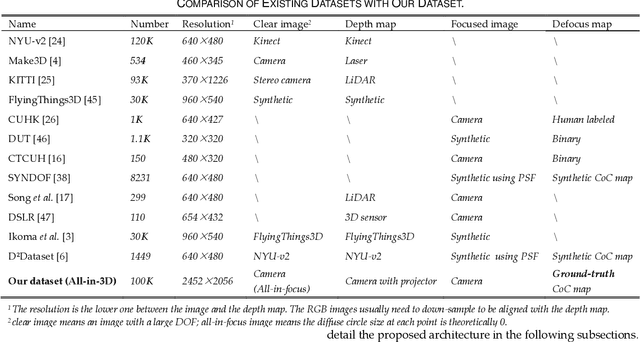

Monocular depth estimation and defocus estimation are two fundamental tasks in computer vision. Most existing methods treat depth estimation and defocus estimation as two separate tasks, ignoring the strong connection between them. In this work, we propose a multi-task learning network consisting of an encoder with two decoders to estimate the depth and defocus map from a single focused image. Through the multi-task network, the depth estimation facilitates the defocus estimation to get better results in the weak texture region and the defocus estimation facilitates the depth estimation by the strong physical connection between the two maps. We set up a dataset (named ALL-in-3D dataset) which is the first all-real image dataset consisting of 100K sets of all-in-focus images, focused images with focus depth, depth maps, and defocus maps. It enables the network to learn features and solid physical connections between the depth and real defocus images. Experiments demonstrate that the network learns more solid features from the real focused images than the synthetic focused images. Benefiting from this multi-task structure where different tasks facilitate each other, our depth and defocus estimations achieve significantly better performance than other state-of-art algorithms. The code and dataset will be publicly available at https://github.com/cubhe/MDDNet.
Precise Point Spread Function Estimation
Mar 06, 2022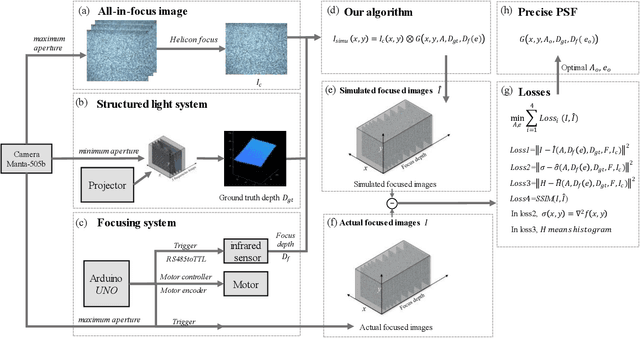

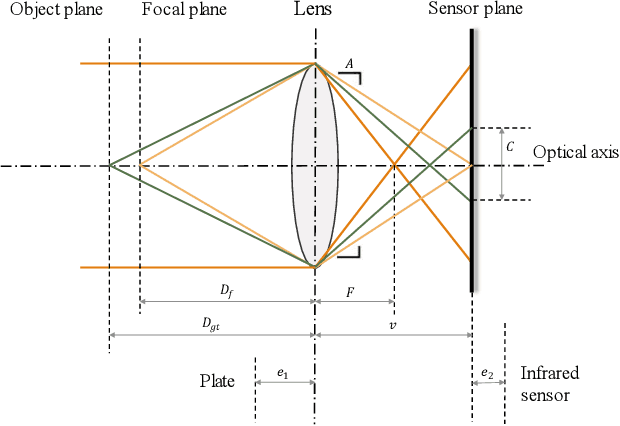
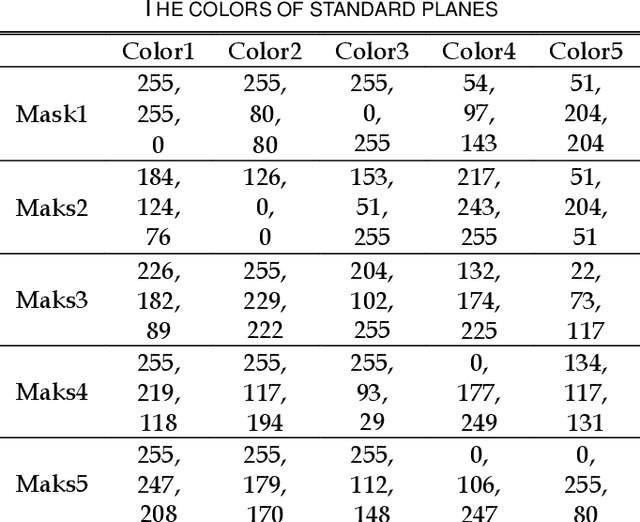
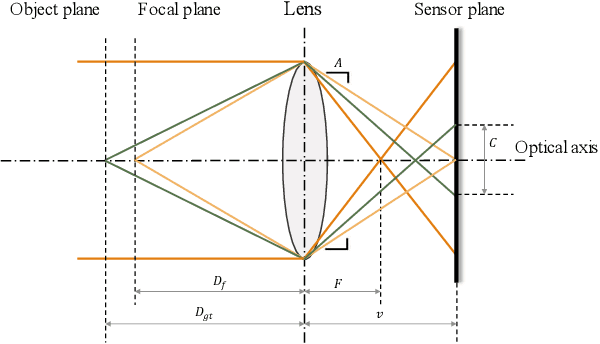
Point spread function (PSF) plays a crucial role in many fields, such as shape from focus/defocus, depth estimation, and imaging process in fluorescence microscopy. However, the mathematical model of the defocus process is still unclear because several variables in the point spread function are hard to measure accurately, such as the f-number of cameras, the physical size of a pixel, the focus depth, etc. In this work, we develop a precise mathematical model of the camera's point spread function to describe the defocus process. We first derive the mathematical algorithm for the PSF and extract two parameters A and e. A is the composite of camera's f-number, pixel-size, output scale, and scaling factor of the circle of confusion; e is the deviation of the focus depth. We design a novel metric based on the defocus histogram to evaluate the difference between the simulated focused image and the actual focused image to obtain optimal A and e. We also construct a hardware system consisting of a focusing system and a structured light system to acquire the all-in-focus image, the focused image with corresponding focus depth, and the depth map in the same view. The three types of images, as a dataset, are used to obtain the precise PSF. Our experiments on standard planes and actual objects show that the proposed algorithm can accurately describe the defocus process. The accuracy of our algorithm is further proved by evaluating the difference among the actual focused images, the focused image generated by our algorithm, the focused image generated by others. The results show that the loss of our algorithm is 40% less than others on average. The dataset, code, and model are available on GitHub: https://github.com/cubhe/ precise-point-spread-function-estimation.