 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reformulate for Linear Programming
Paper and Code
Jan 17, 2022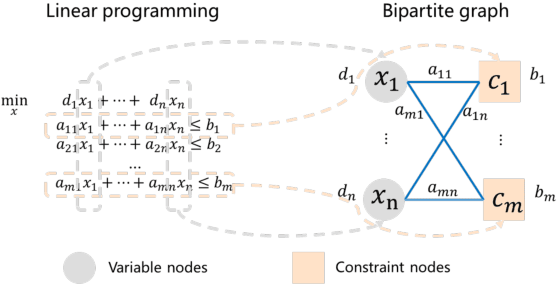

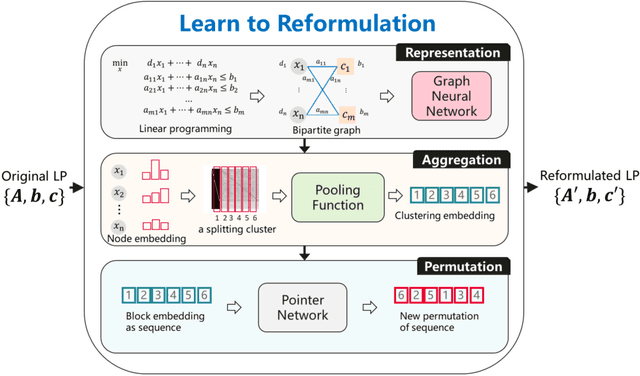
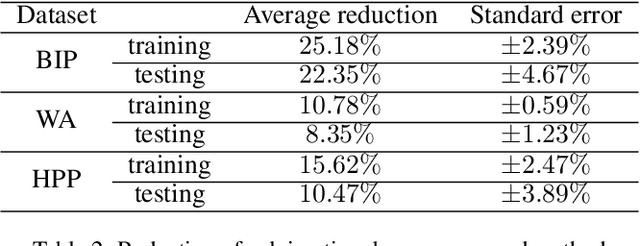
It has been verified that the linear programming (LP) is able to formulate many real-life optimization problems, which can obtain the optimum by resorting to corresponding solvers such as OptVerse, Gurobi and CPLEX. In the past decades, a serial of traditional operation research algorithms have been proposed to obtain the optimum of a given LP in a fewer solving time. Recently, there is a trend of using machine learning (ML) techniques to improve the performance of above solvers. However, almost no previous work takes advantage of ML techniques to improve the performance of solver from the front end, i.e., the modeling (or formulation). In this paper, we are the first to propose a reinforcement learning-based reformulation method for LP to improve the performance of solving process. Using an open-source solver COIN-OR LP (CLP) as an environment, we implement the proposed method over two public research LP datasets and one large-scale LP dataset collected from practical production planning scenario. The evaluation results suggest that the proposed method can effectively reduce both the solving iteration number ($25\%\downarrow$) and the solving time ($15\%\downarrow$) over above datasets in average, compared to directly solving the original LP instances.