 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOFA: Modular Factorial Design for Hyperparameter Optimization
Paper and Code
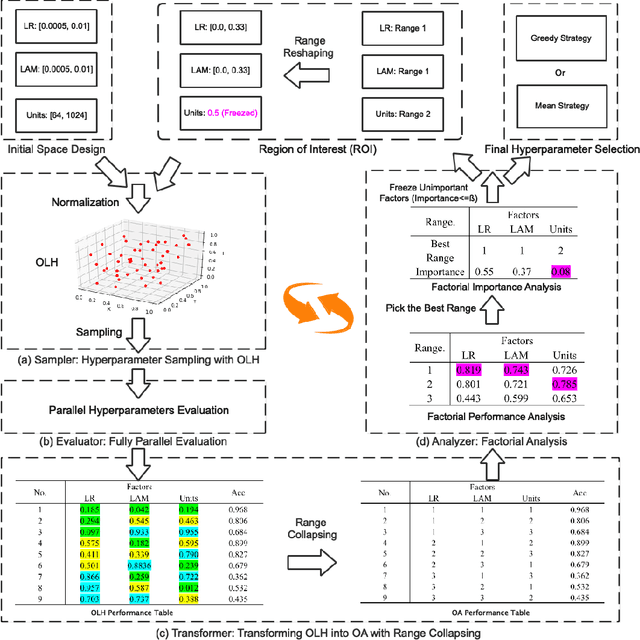
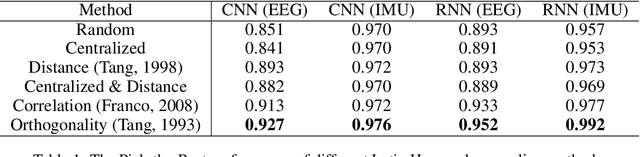
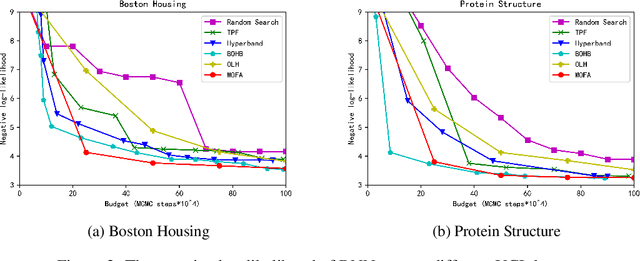
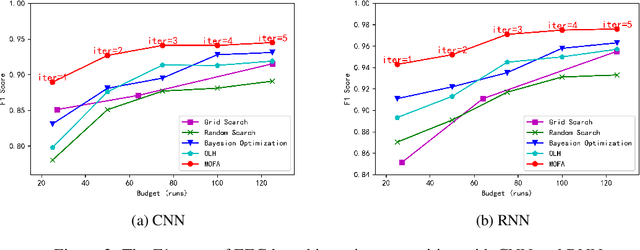
Automated hyperparameter optimization (HPO) has shown great power in many machine learning applications. While existing methods suffer from model selection, parallelism, or sample efficiency, this paper presents a new HPO method, MOdular FActorial Design (MOFA), to address these issues simultaneously. The major idea is to use techniques from Experimental Designs to improve sample efficiency of model-free methods. Particularly, MOFA runs with four modules in each iteration: (1) an Orthogonal Latin Hypercube (OLH)-based sampler preserving both univariate projection uniformity and orthogonality; (2) a highly parallelized evaluator; (3) a transformer to collapse the OLH performance table into a specified Fractional Factorial Design--Orthogonal Array (OA); (4) an analyzer including Factorial Performance Analysis and Factorial Importance Analysis to narrow down the search space. We theoretically and empirically show that MOFA has great advantages over existing model-based and model-free methods.