 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning PAC-Bayes Priors in Model Averaging
Paper and Code
Dec 25, 2019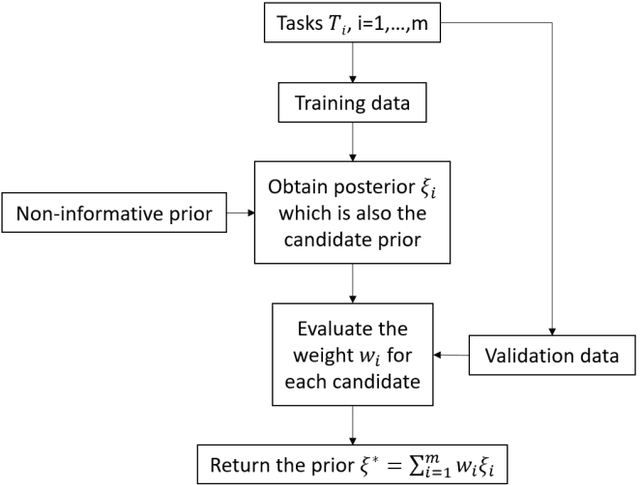

Nowadays model uncertainty has become one of the most important problems in both academia and industry. In this paper, we mainly consider the scenario in which we have a common model set used for model averaging instead of selecting a single final model via a model selection procedure to account for this model's uncertainty to improve reliability and accuracy of inferences. Here one main challenge is to learn the prior over the model set. To tackle this problem, we propose two data-based algorithms to get proper priors for model averaging. One is for meta-learner, the analysts should use historical similar tasks to extract the information about the prior. The other one is for base-learner, a subsampling method is used to deal with the data step by step. Theoretically, an upper bound of risk for our algorithm is presented to guarantee the performance of the worst situation. In practice, both methods perform well in simulations and real data studies, especially with poor quality data.