 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPBERT: Efficient Inference for BERT based on Dynamic Planning
Jul 26, 2023



Large-scale pre-trained language models such as BERT have contributed significantly to the development of NLP. However, those models require large computational resources, making it difficult to be applied to mobile devices where computing power is limited. In this paper we aim to address the weakness of existing input-adaptive inference methods which fail to take full advantage of the structure of BERT. We propose Dynamic Planning in BERT, a novel fine-tuning strategy that can accelerate the inference process of BERT through selecting a subsequence of transformer layers list of backbone as a computational path for an input sample. To do this, our approach adds a planning module to the original BERT model to determine whether a layer is included or bypassed during inference. Experimental results on the GLUE benchmark exhibit that our method reduces latency to 75\% while maintaining 98\% accuracy, yielding a better accuracy-speed trade-off compared to state-of-the-art input-adaptive methods.
Locally Adaptive Learning Loss for Semantic Image Segmentation
Apr 16, 2018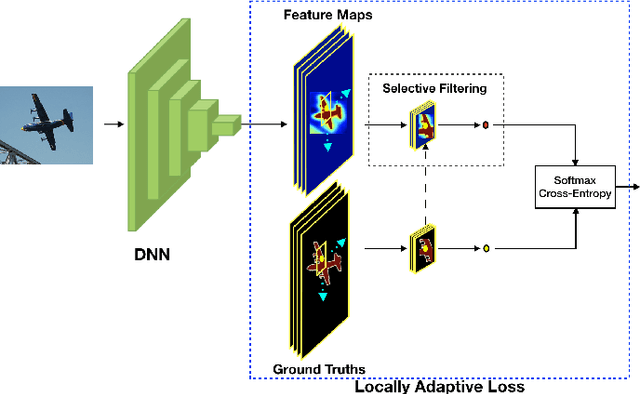

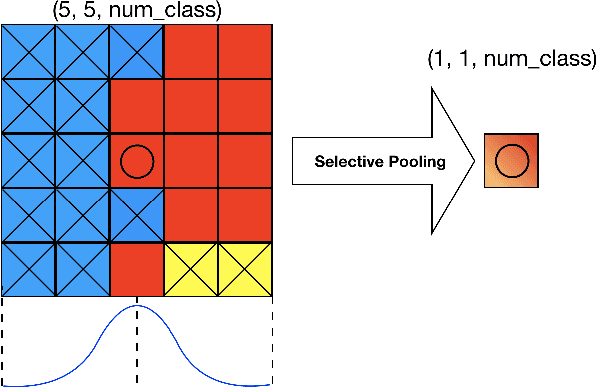

We propose a novel locally adaptive learning estimator for enhancing the inter- and intra- discriminative capabilities of Deep Neural Networks, which can be used as improved loss layer for semantic image segmentation tasks. Most loss layers compute pixel-wise cost between feature maps and ground truths, ignoring spatial layouts and interactions between neighboring pixels with same object category, and thus networks cannot be effectively sensitive to intra-class connections. Stride by stride, our method firstly conducts adaptive pooling filter operating over predicted feature maps, aiming to merge predicted distributions over a small group of neighboring pixels with same category, and then it computes cost between the merged distribution vector and their category label. Such design can make groups of neighboring predictions from same category involved into estimations on predicting correctness with respect to their category, and hence train networks to be more sensitive to regional connections between adjacent pixels based on their categories. In the experiments on Pascal VOC 2012 segmentation datasets, the consistently improved results show that our proposed approach achieves better segmentation masks against previous counterparts.