 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIFT: Stochastic Hidden-Trajectory Deflection for Removing Diffusion-based Watermark
Apr 01, 2026Diffusion-based watermarking methods embed verifiable marks by manipulating the initial noise or the reverse diffusion trajectory. However, these methods share a critical assumption: verification can succeed only if the diffusion trajectory can be faithfully reconstructed. This reliance on trajectory recovery constitutes a fundamental and exploitable vulnerability. We propose $\underline{\mathbf{S}}$tochastic $\underline{\mathbf{Hi}}$dden-Trajectory De$\underline{\mathbf{f}}$lec$\underline{\mathbf{t}}$ion ($\mathbf{SHIFT}$), a training-free attack that exploits this common weakness across diverse watermarking paradigms. SHIFT leverages stochastic diffusion resampling to deflect the generative trajectory in latent space, making the reconstructed image statistically decoupled from the original watermark-embedded trajectory while preserving strong visual quality and semantic consistency. Extensive experiments on nine representative watermarking methods spanning noise-space, frequency-domain, and optimization-based paradigms show that SHIFT achieves 95%--100% attack success rates with nearly no loss in semantic quality, without requiring any watermark-specific knowledge or model retraining.
What can LLM tell us about cities?
Nov 25, 2024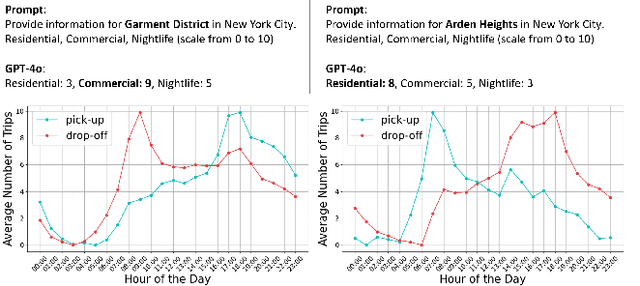
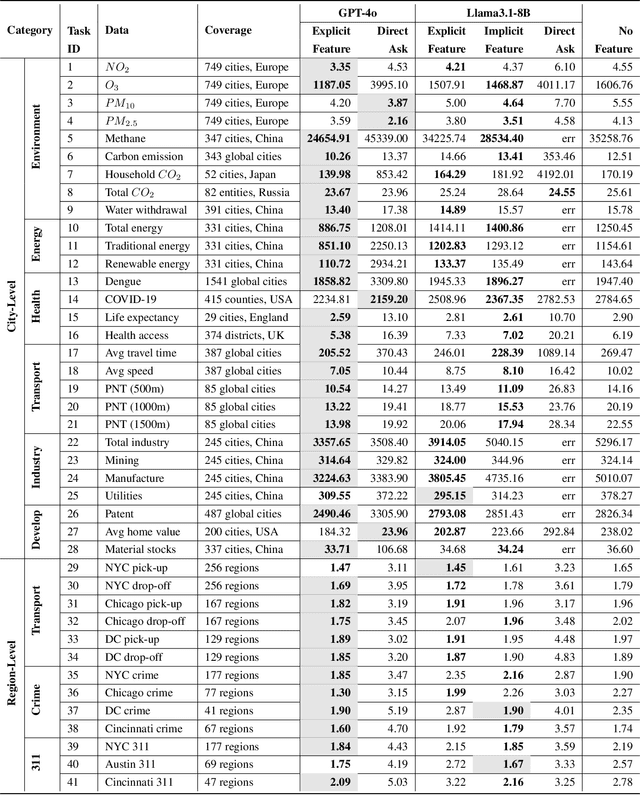
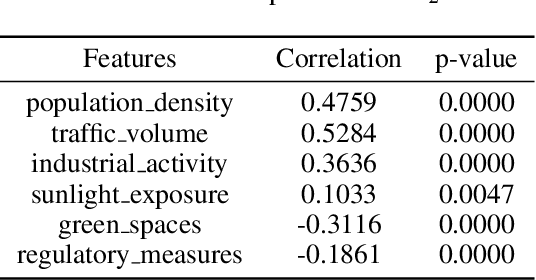
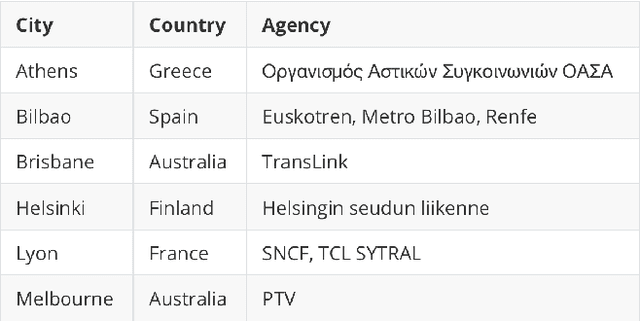
This study explores the capabilities of large language models (LLMs) in providing knowledge about cities and regions on a global scale. We employ two methods: directly querying the LLM for target variable values and extracting explicit and implicit features from the LLM correlated with the target variable. Our experiments reveal that LLMs embed a broad but varying degree of knowledge across global cities, with ML models trained on LLM-derived features consistently leading to improved predictive accuracy. Additionally, we observe that LLMs demonstrate a certain level of knowledge across global cities on all continents, but it is evident when they lack knowledge, as they tend to generate generic or random outputs for unfamiliar tasks. These findings suggest that LLMs can offer new opportunities for data-driven decision-making in the study of cities.
FGN: Fusion Glyph Network for Chinese Named Entity Recognition
Feb 14, 2020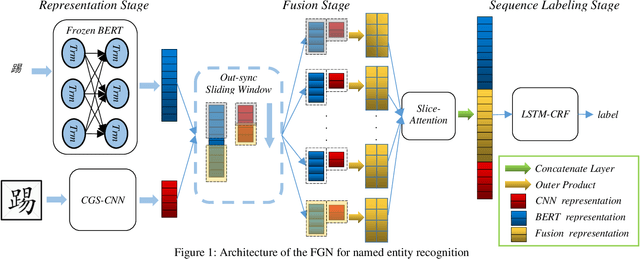

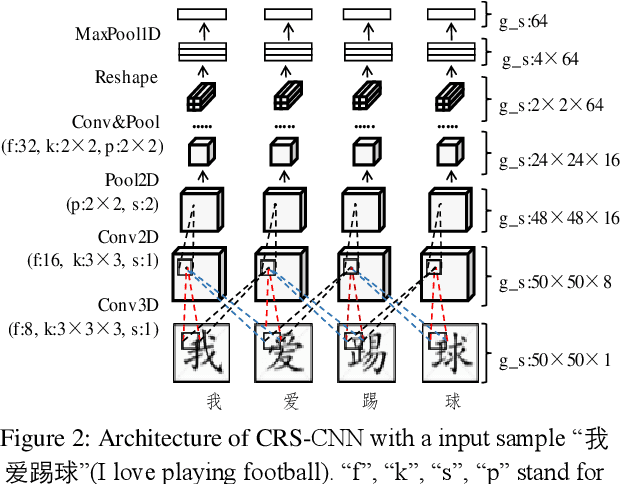

Chinese NER is a challenging task. As pictographs, Chinese characters contain latent glyph information, which is often overlooked. We propose the FGN, Fusion Glyph Network for Chinese NER. This method may offer glyph information for fusion representation learning with BERT. The major innovations of FGN include: (1) a novel CNN structure called CGS-CNN is proposed to capture glyph information from both character graphs and their neighboring graphs. (2) we provide a method with sliding window and Slice-Attention to extract interactive information between BERT representation and glyph representation. Experiments are conducted on four NER datasets, showing that FGN with LSTM-CRF as tagger achieves new state-of-the-arts performance for Chinese NER. Further, more experiments are conducted to investigate the influences of various components and settings in FGN.