 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondTSF: One-line Plugin of Dataset Condensation for Time Series Forecasting
Jun 04, 2024



Dataset condensation is a newborn technique that generates a small dataset that can be used in training deep neural networks to lower training costs. The objective of dataset condensation is to ensure that the model trained with the synthetic dataset can perform comparably to the model trained with full datasets. However, existing methods predominantly concentrate on classification tasks, posing challenges in their adaptation to time series forecasting (TS-forecasting). This challenge arises from disparities in the evaluation of synthetic data. In classification, the synthetic data is considered well-distilled if the model trained with the full dataset and the model trained with the synthetic dataset yield identical labels for the same input, regardless of variations in output logits distribution. Conversely, in TS-forecasting, the effectiveness of synthetic data distillation is determined by the distance between predictions of the two models. The synthetic data is deemed well-distilled only when all data points within the predictions are similar. Consequently, TS-forecasting has a more rigorous evaluation methodology compared to classification. To mitigate this gap, we theoretically analyze the optimization objective of dataset condensation for TS-forecasting and propose a new one-line plugin of dataset condensation designated as Dataset Condensation for Time Series Forecasting (CondTSF) based on our analysis. Plugging CondTSF into previous dataset condensation methods facilitates a reduction in the distance between the predictions of the model trained with the full dataset and the model trained with the synthetic dataset, thereby enhancing performance. We conduct extensive experiments on eight commonly used time series datasets. CondTSF consistently improves the performance of all previous dataset condensation methods across all datasets, particularly at low condensing ratios.
Prediction with Incomplete Data under Agnostic Mask Distribution Shift
May 18, 2023



Data with missing values is ubiquitous in many applications. Recent years have witnessed increasing attention on prediction with only incomplete data consisting of observed features and a mask that indicates the missing pattern. Existing methods assume that the training and testing distributions are the same, which may be violated in real-world scenarios. In this paper, we consider prediction with incomplete data in the presence of distribution shift. We focus on the case where the underlying joint distribution of complete features and label is invariant, but the missing pattern, i.e., mask distribution may shift agnostically between training and testing. To achieve generalization, we leverage the observation that for each mask, there is an invariant optimal predictor. To avoid the exponential explosion when learning them separately, we approximate the optimal predictors jointly using a double parameterization technique. This has the undesirable side effect of allowing the learned predictors to rely on the intra-mask correlation and that between features and mask. We perform decorrelation to minimize this effect. Combining the techniques above, we propose a novel prediction method called StableMiss. Extensive experiments on both synthetic and real-world datasets show that StableMiss is robust and outperforms state-of-the-art methods under agnostic mask distribution shift.
User-Oriented Robust Reinforcement Learning
Feb 18, 2022



Recently, improving the robustness of policies across different environments attracts increasing attention in the reinforcement learning (RL) community. Existing robust RL methods mostly aim to achieve the max-min robustness by optimizing the policy's performance in the worst-case environment. However, in practice, a user that uses an RL policy may have different preferences over its performance across environments. Clearly, the aforementioned max-min robustness is oftentimes too conservative to satisfy user preference. Therefore, in this paper, we integrate user preference into policy learning in robust RL, and propose a novel User-Oriented Robust RL (UOR-RL) framework. Specifically, we define a new User-Oriented Robustness (UOR) metric for RL, which allocates different weights to the environments according to user preference and generalizes the max-min robustness metric. To optimize the UOR metric, we develop two different UOR-RL training algorithms for the scenarios with or without a priori known environment distribution, respectively. Theoretically, we prove that our UOR-RL training algorithms converge to near-optimal policies even with inaccurate or completely no knowledge about the environment distribution. Furthermore, we carry out extensive experimental evaluations in 4 MuJoCo tasks. The experimental results demonstrate that UOR-RL is comparable to the state-of-the-art baselines under the average and worst-case performance metrics, and more importantly establishes new state-of-the-art performance under the UOR metric.
DeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning
Nov 10, 2021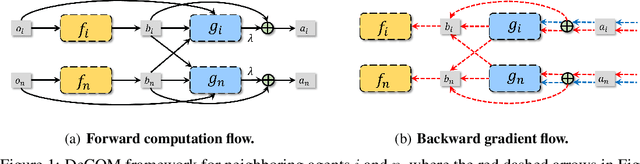
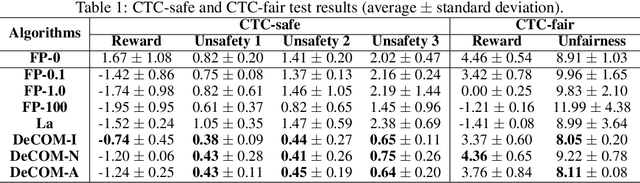
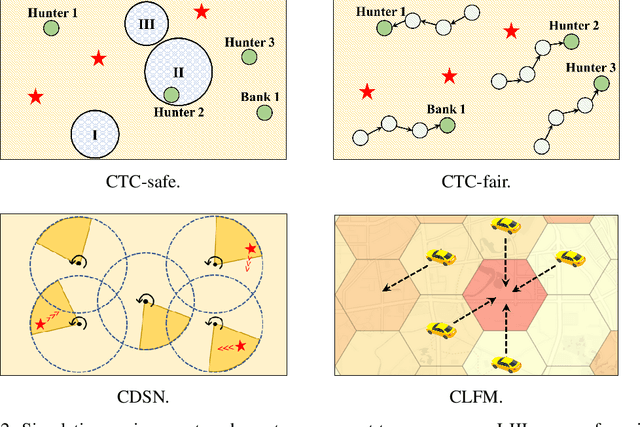
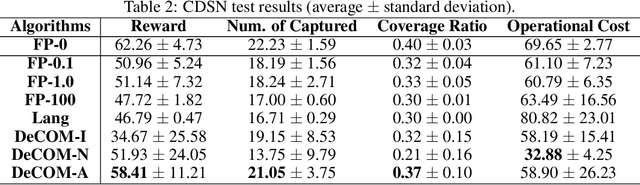
In recent years, multi-agent reinforcement learning (MARL) has presented impressive performance in various applications. However, physical limitations, budget restrictions, and many other factors usually impose \textit{constraints} on a multi-agent system (MAS), which cannot be handled by traditional MARL frameworks. Specifically, this paper focuses on constrained MASes where agents work \textit{cooperatively} to maximize the expected team-average return under various constraints on expected team-average costs, and develops a \textit{constrained cooperative MARL} framework, named DeCOM, for such MASes. In particular, DeCOM decomposes the policy of each agent into two modules, which empowers information sharing among agents to achieve better cooperation. In addition, with such modularization, the training algorithm of DeCOM separates the original constrained optimization into an unconstrained optimization on reward and a constraints satisfaction problem on costs. DeCOM then iteratively solves these problems in a computationally efficient manner, which makes DeCOM highly scalable. We also provide theoretical guarantees on the convergence of DeCOM's policy update algorithm. Finally, we validate the effectiveness of DeCOM with various types of costs in both toy and large-scale (with 500 agents) environments.
Networked Time Series Prediction with Incomplete Data
Oct 05, 2021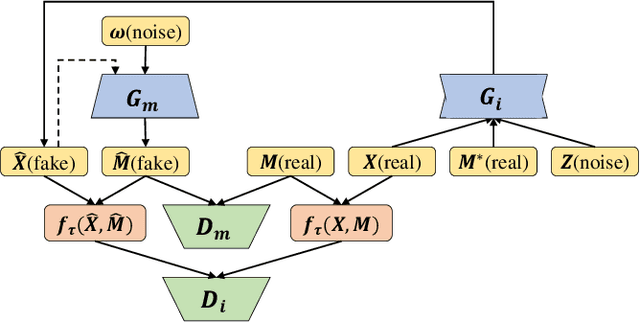
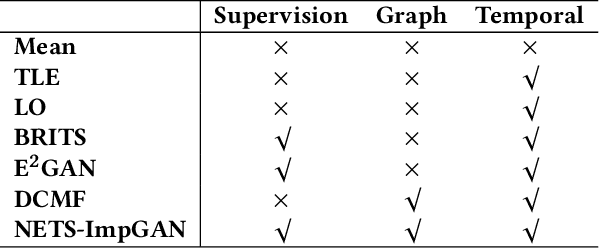
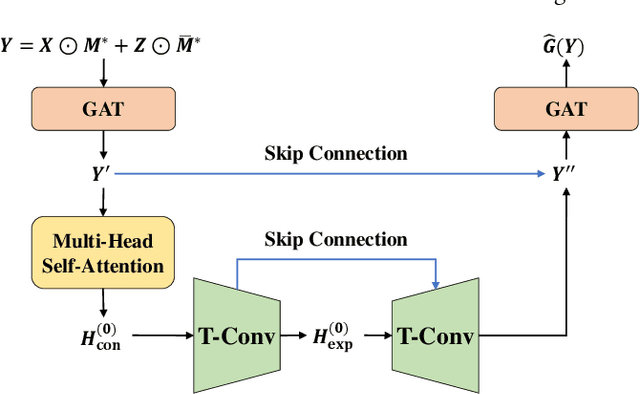
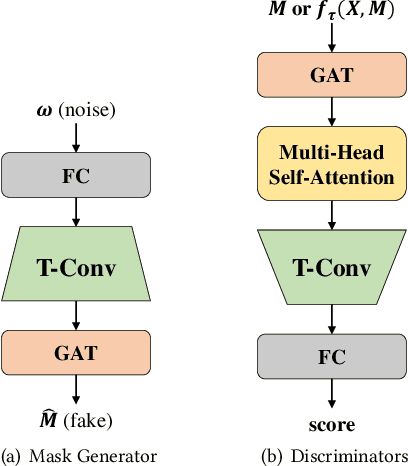
A networked time series (NETS) is a family of time series on a given graph, one for each node. It has found a wide range of applications from intelligent transportation, environment monitoring to mobile network management. An important task in such applications is to predict the future values of a NETS based on its historical values and the underlying graph. Most existing methods require complete data for training. However, in real-world scenarios, it is not uncommon to have missing data due to sensor malfunction, incomplete sensing coverage, etc. In this paper, we study the problem of NETS prediction with incomplete data. We propose NETS-ImpGAN, a novel deep learning framework that can be trained on incomplete data with missing values in both history and future. Furthermore, we propose novel Graph Temporal Attention Networks by incorporating the attention mechanism to capture both inter-time series correlations and temporal correlations. We conduct extensive experiments on three real-world datasets under different missing patterns and missing rates. The experimental results show that NETS-ImpGAN outperforms existing methods except when data exhibit very low variance, in which case NETS-ImpGAN still achieves competitive performance.
CityFlow: A Multi-Agent Reinforcement Learning Environment for Large Scale City Traffic Scenario
May 13, 2019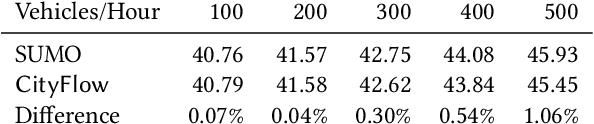
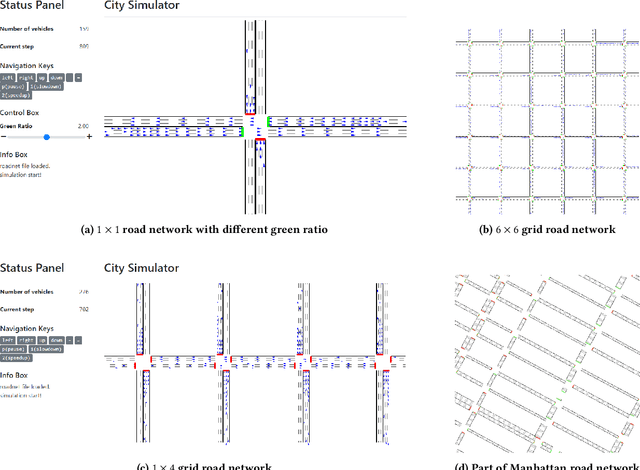
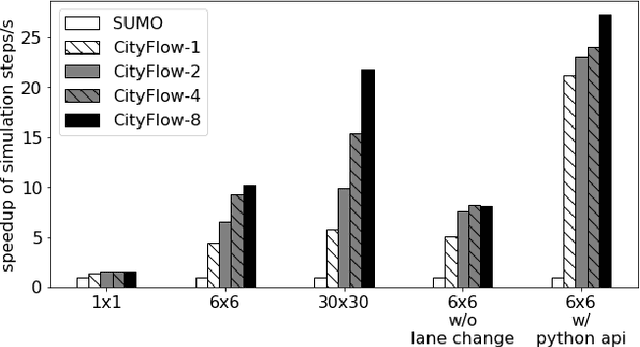
Traffic signal control is an emerging application scenario for reinforcement learning. Besides being as an important problem that affects people's daily life in commuting, traffic signal control poses its unique challenges for reinforcement learning in terms of adapting to dynamic traffic environment and coordinating thousands of agents including vehicles and pedestrians. A key factor in the success of modern reinforcement learning relies on a good simulator to generate a large number of data samples for learning. The most commonly used open-source traffic simulator SUMO is, however, not scalable to large road network and large traffic flow, which hinders the study of reinforcement learning on traffic scenarios. This motivates us to create a new traffic simulator CityFlow with fundamentally optimized data structures and efficient algorithms. CityFlow can support flexible definitions for road network and traffic flow based on synthetic and real-world data. It also provides user-friendly interface for reinforcement learning. Most importantly, CityFlow is more than twenty times faster than SUMO and is capable of supporting city-wide traffic simulation with an interactive render for monitoring. Besides traffic signal control, CityFlow could serve as the base for other transportation studies and can create new possibilities to test machine learning methods in the intelligent transportation domain.