 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Oriented Robust Reinforcement Learning
Feb 18, 2022



Recently, improving the robustness of policies across different environments attracts increasing attention in the reinforcement learning (RL) community. Existing robust RL methods mostly aim to achieve the max-min robustness by optimizing the policy's performance in the worst-case environment. However, in practice, a user that uses an RL policy may have different preferences over its performance across environments. Clearly, the aforementioned max-min robustness is oftentimes too conservative to satisfy user preference. Therefore, in this paper, we integrate user preference into policy learning in robust RL, and propose a novel User-Oriented Robust RL (UOR-RL) framework. Specifically, we define a new User-Oriented Robustness (UOR) metric for RL, which allocates different weights to the environments according to user preference and generalizes the max-min robustness metric. To optimize the UOR metric, we develop two different UOR-RL training algorithms for the scenarios with or without a priori known environment distribution, respectively. Theoretically, we prove that our UOR-RL training algorithms converge to near-optimal policies even with inaccurate or completely no knowledge about the environment distribution. Furthermore, we carry out extensive experimental evaluations in 4 MuJoCo tasks. The experimental results demonstrate that UOR-RL is comparable to the state-of-the-art baselines under the average and worst-case performance metrics, and more importantly establishes new state-of-the-art performance under the UOR metric.
DeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning
Nov 10, 2021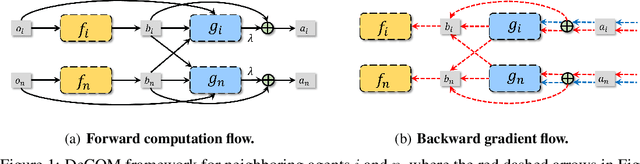
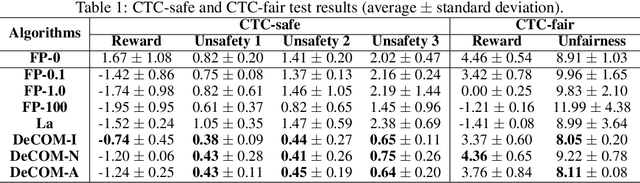
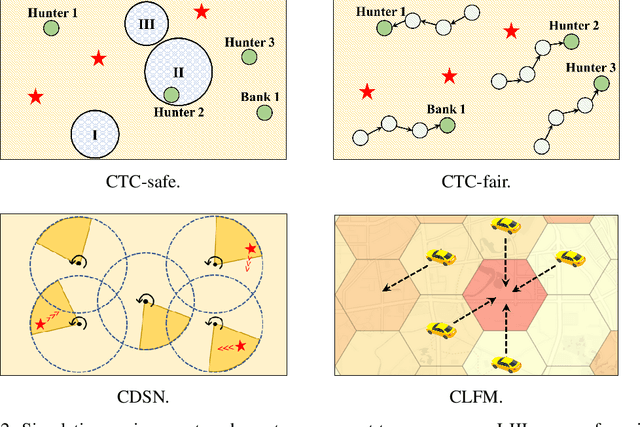
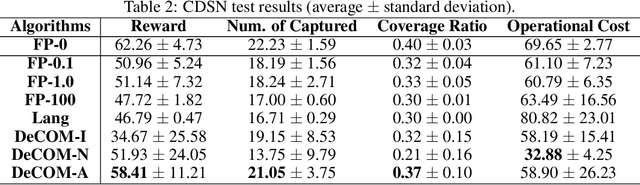
In recent years, multi-agent reinforcement learning (MARL) has presented impressive performance in various applications. However, physical limitations, budget restrictions, and many other factors usually impose \textit{constraints} on a multi-agent system (MAS), which cannot be handled by traditional MARL frameworks. Specifically, this paper focuses on constrained MASes where agents work \textit{cooperatively} to maximize the expected team-average return under various constraints on expected team-average costs, and develops a \textit{constrained cooperative MARL} framework, named DeCOM, for such MASes. In particular, DeCOM decomposes the policy of each agent into two modules, which empowers information sharing among agents to achieve better cooperation. In addition, with such modularization, the training algorithm of DeCOM separates the original constrained optimization into an unconstrained optimization on reward and a constraints satisfaction problem on costs. DeCOM then iteratively solves these problems in a computationally efficient manner, which makes DeCOM highly scalable. We also provide theoretical guarantees on the convergence of DeCOM's policy update algorithm. Finally, we validate the effectiveness of DeCOM with various types of costs in both toy and large-scale (with 500 agents) environments.