 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning
Nov 10, 2021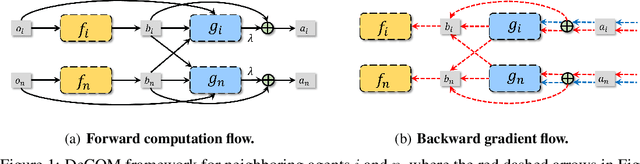
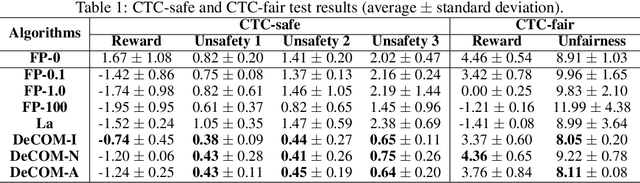
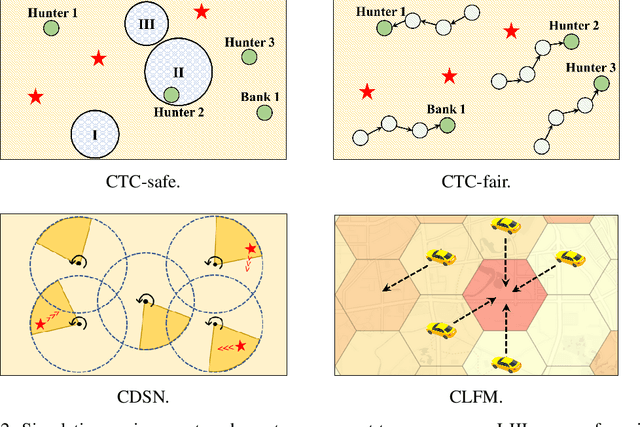
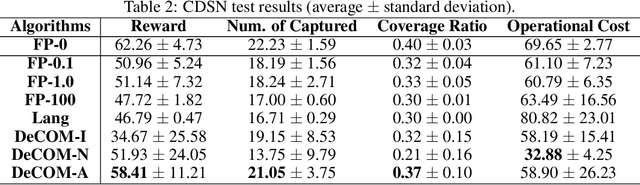
In recent years, multi-agent reinforcement learning (MARL) has presented impressive performance in various applications. However, physical limitations, budget restrictions, and many other factors usually impose \textit{constraints} on a multi-agent system (MAS), which cannot be handled by traditional MARL frameworks. Specifically, this paper focuses on constrained MASes where agents work \textit{cooperatively} to maximize the expected team-average return under various constraints on expected team-average costs, and develops a \textit{constrained cooperative MARL} framework, named DeCOM, for such MASes. In particular, DeCOM decomposes the policy of each agent into two modules, which empowers information sharing among agents to achieve better cooperation. In addition, with such modularization, the training algorithm of DeCOM separates the original constrained optimization into an unconstrained optimization on reward and a constraints satisfaction problem on costs. DeCOM then iteratively solves these problems in a computationally efficient manner, which makes DeCOM highly scalable. We also provide theoretical guarantees on the convergence of DeCOM's policy update algorithm. Finally, we validate the effectiveness of DeCOM with various types of costs in both toy and large-scale (with 500 agents) environments.