 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Large Language Models for Disaster Management: A Survey
Jan 12, 2025



Large language models (LLMs) have revolutionized scientific research with their exceptional capabilities and transformed various fields. Among their practical applications, LLMs have been playing a crucial role in mitigating threats to human life, infrastructure, and the environment. Despite growing research in disaster LLMs, there remains a lack of systematic review and in-depth analysis of LLMs for natural disaster management. To address the gap, this paper presents a comprehensive survey of existing LLMs in natural disaster management, along with a taxonomy that categorizes existing works based on disaster phases and application scenarios. By collecting public datasets and identifying key challenges and opportunities, this study aims to guide the professional community in developing advanced LLMs for disaster management to enhance the resilience against natural disasters.
Evolutionary Programmer: Autonomously Creating Path Planning Programs based on Evolutionary Algorithms
Mar 30, 2022



Evolutionary algorithms are wildly used in unmanned aerial vehicle path planning for their flexibility and effectiveness. Nevertheless, they are so sensitive to the change of environment that can't adapt to all scenarios. Due to this drawback, the previously successful planner frequently fail in a new scene. In this paper, a first-of-its-kind machine learning method named Evolutionary Programmer is proposed to solve this problem. Concretely, the most commonly used Evolutionary Algorithms are decomposed into a series of operators, which constitute the operator library of the system. The new method recompose the operators to a integrated planner, thus, the most suitable operators can be selected for adapting to the changing circumstances. Different from normal machine programmers, this method focuses on a specific task with high-level integrated instructions and thus alleviate the problem of huge search space caused by the briefness of instructions. On this basis, a 64-bit sequence is presented to represent path planner and then evolved with the modified Genetic Algorithm. Finally, the most suitable planner is created by utilizing the information of the previous planner and various randomly generated ones.
DeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning
Nov 10, 2021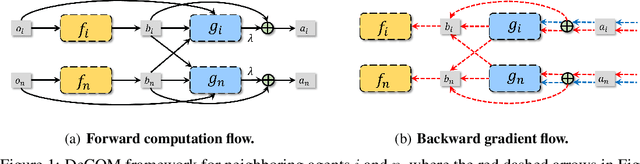
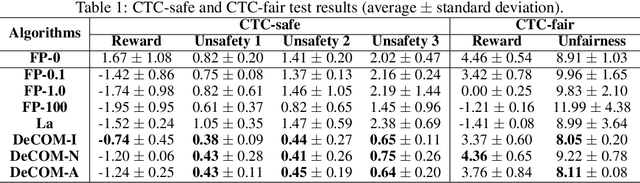
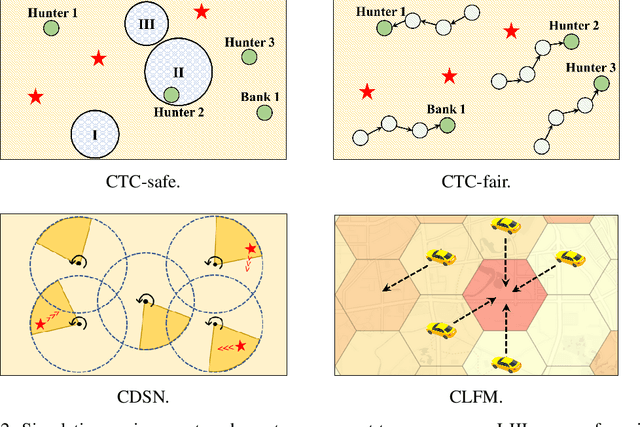
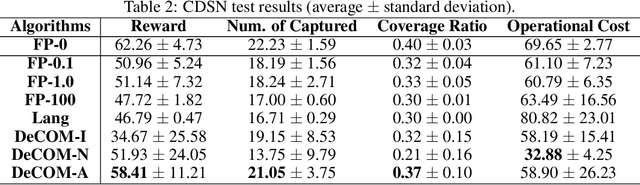
In recent years, multi-agent reinforcement learning (MARL) has presented impressive performance in various applications. However, physical limitations, budget restrictions, and many other factors usually impose \textit{constraints} on a multi-agent system (MAS), which cannot be handled by traditional MARL frameworks. Specifically, this paper focuses on constrained MASes where agents work \textit{cooperatively} to maximize the expected team-average return under various constraints on expected team-average costs, and develops a \textit{constrained cooperative MARL} framework, named DeCOM, for such MASes. In particular, DeCOM decomposes the policy of each agent into two modules, which empowers information sharing among agents to achieve better cooperation. In addition, with such modularization, the training algorithm of DeCOM separates the original constrained optimization into an unconstrained optimization on reward and a constraints satisfaction problem on costs. DeCOM then iteratively solves these problems in a computationally efficient manner, which makes DeCOM highly scalable. We also provide theoretical guarantees on the convergence of DeCOM's policy update algorithm. Finally, we validate the effectiveness of DeCOM with various types of costs in both toy and large-scale (with 500 agents) environments.