 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Cooperative behaviour in Sequential-Social dilemmas through Multi-Agent Reinforcement Learning using Status-Quo Loss
Paper and Code
Feb 13, 2020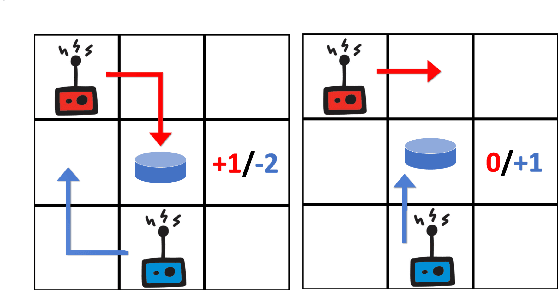


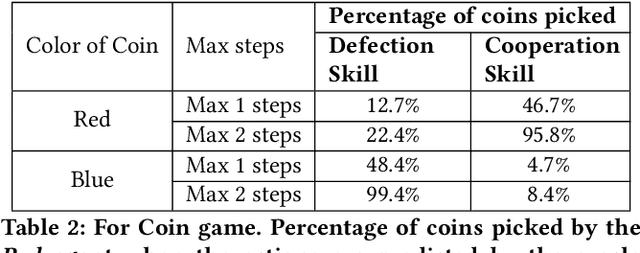
In social dilemma situations, individual rationality leads to sub-optimal group outcomes. Several human engagements can be modeled as a sequential (multi-step) social dilemmas. However, in contrast to humans, Deep Reinforcement Learning agents trained to optimize individual rewards in sequential social dilemmas converge to selfish, mutually harmful behavior. We introduce a status-quo loss (SQLoss) that encourages an agent to stick to the status quo, rather than repeatedly changing its policy. We show how agents trained with SQLoss evolve cooperative behavior in several social dilemma matrix games. To work with social dilemma games that have visual input, we propose GameDistill. GameDistill uses self-supervision and clustering to automatically extract cooperative and selfish policies from a social dilemma game. We combine GameDistill and SQLoss to show how agents evolve socially desirable cooperative behavior in the Coin Game.