 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Wildfire Localization on the NASA Autonomous Modular Sensor using Deep Learning
Jan 20, 2026High-altitude, multi-spectral, aerial imagery is scarce and expensive to acquire, yet it is necessary for algorithmic advances and application of machine learning models to high-impact problems such as wildfire detection. We introduce a human-annotated dataset from the NASA Autonomous Modular Sensor (AMS) using 12-channel, medium to high altitude (3 - 50 km) aerial wildfire images similar to those used in current US wildfire missions. Our dataset combines spectral data from 12 different channels, including infrared (IR), short-wave IR (SWIR), and thermal. We take imagery from 20 wildfire missions and randomly sample small patches to generate over 4000 images with high variability, including occlusions by smoke/clouds, easily-confused false positives, and nighttime imagery. We demonstrate results from a deep-learning model to automate the human-intensive process of fire perimeter determination. We train two deep neural networks, one for image classification and the other for pixel-level segmentation. The networks are combined into a unique real-time segmentation model to efficiently localize active wildfire on an incoming image feed. Our model achieves 96% classification accuracy, 74% Intersection-over-Union(IoU), and 84% recall surpassing past methods, including models trained on satellite data and classical color-rule algorithms. By leveraging a multi-spectral dataset, our model is able to detect active wildfire at nighttime and behind clouds, while distinguishing between false positives. We find that data from the SWIR, IR, and thermal bands is the most important to distinguish fire perimeters. Our code and dataset can be found here: https://github.com/nasa/Autonomous-Modular-Sensor-Wildfire-Segmentation/tree/main and https://drive.google.com/drive/folders/1-u4vs9rqwkwgdeeeoUhftCxrfe_4QPTn?=usp=drive_link
* 16 pages, 9 figures, published at AIAA SciTech 2026
Learning Visual Parkour from Generated Images
Oct 31, 2024


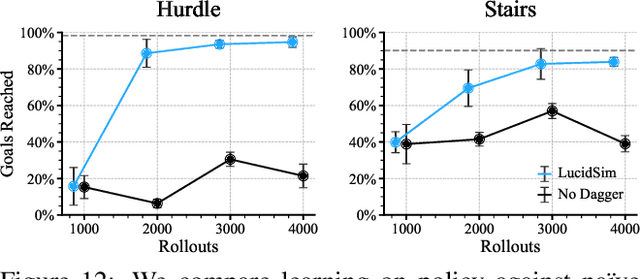
Fast and accurate physics simulation is an essential component of robot learning, where robots can explore failure scenarios that are difficult to produce in the real world and learn from unlimited on-policy data. Yet, it remains challenging to incorporate RGB-color perception into the sim-to-real pipeline that matches the real world in its richness and realism. In this work, we train a robot dog in simulation for visual parkour. We propose a way to use generative models to synthesize diverse and physically accurate image sequences of the scene from the robot's ego-centric perspective. We present demonstrations of zero-shot transfer to the RGB-only observations of the real world on a robot equipped with a low-cost, off-the-shelf color camera. website visit https://lucidsim.github.io
Combining Planning and Diffusion for Mobility with Unknown Dynamics
Oct 09, 2024



Manipulation of large objects over long horizons (such as carts in a warehouse) is an essential skill for deployable robotic systems. Large objects require mobile manipulation which involves simultaneous manipulation, navigation, and movement with the object in tow. In many real-world situations, object dynamics are incredibly complex, such as the interaction of an office chair (with a rotating base and five caster wheels) and the ground. We present a hierarchical algorithm for long-horizon robot manipulation problems in which the dynamics are partially unknown. We observe that diffusion-based behavior cloning is highly effective for short-horizon problems with unknown dynamics, so we decompose the problem into an abstract high-level, obstacle-aware motion-planning problem that produces a waypoint sequence. We use a short-horizon, relative-motion diffusion policy to achieve the waypoints in sequence. We train mobile manipulation policies on a Spot robot that has to push and pull an office chair. Our hierarchical manipulation policy performs consistently better, especially when the horizon increases, compared to a diffusion policy trained on long-horizon demonstrations or motion planning assuming a rigidly-attached object (success rate of 8 (versus 0 and 5 respectively) out of 10 runs). Importantly, our learned policy generalizes to new layouts, grasps, chairs, and flooring that induces more friction, without any further training, showing promise for other complex mobile manipulation problems. Project Page: https://yravan.github.io/plannerorderedpolicy/