 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Speaker-specific Lip-to-Speech Generation
Jun 04, 2022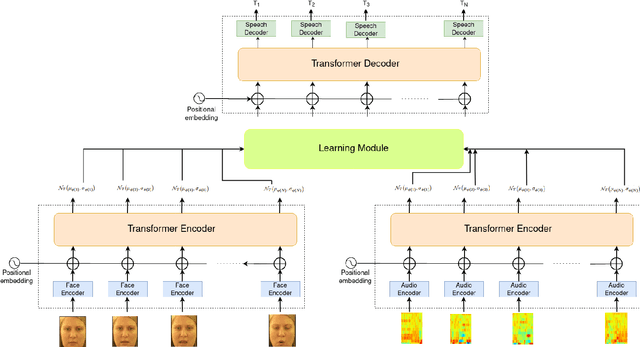
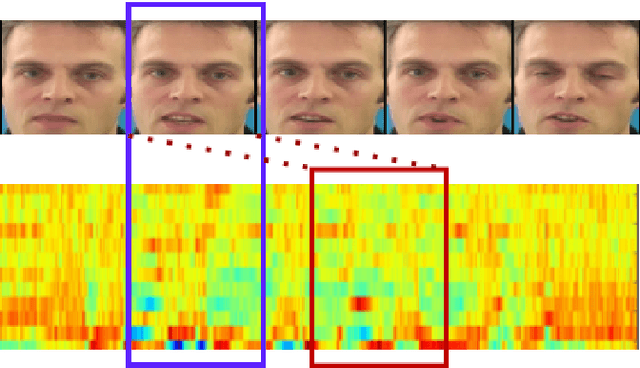
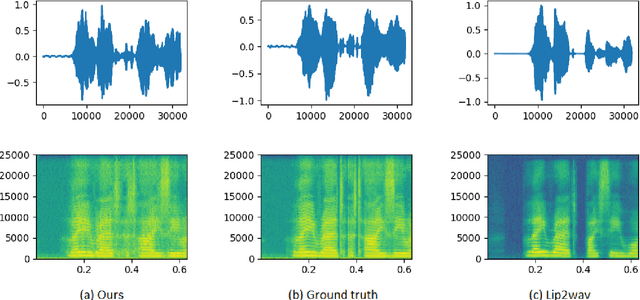
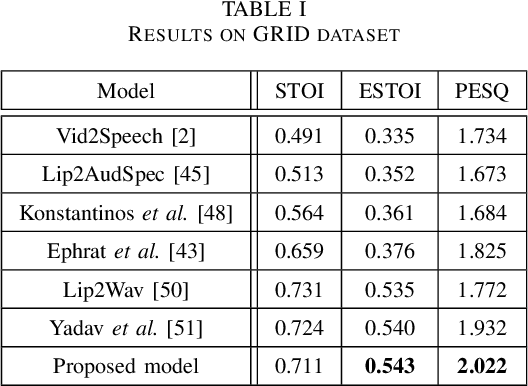
Understanding the lip movement and inferring the speech from it is notoriously difficult for the common person. The task of accurate lip-reading gets help from various cues of the speaker and its contextual or environmental setting. Every speaker has a different accent and speaking style, which can be inferred from their visual and speech features. This work aims to understand the correlation/mapping between speech and the sequence of lip movement of individual speakers in an unconstrained and large vocabulary. We model the frame sequence as a prior to the transformer in an auto-encoder setting and learned a joint embedding that exploits temporal properties of both audio and video. We learn temporal synchronization using deep metric learning, which guides the decoder to generate speech in sync with input lip movements. The predictive posterior thus gives us the generated speech in speaker speaking style. We have trained our model on the Grid and Lip2Wav Chemistry lecture dataset to evaluate single speaker natural speech generation tasks from lip movement in an unconstrained natural setting. Extensive evaluation using various qualitative and quantitative metrics with human evaluation also shows that our method outperforms the Lip2Wav Chemistry dataset(large vocabulary in an unconstrained setting) by a good margin across almost all evaluation metrics and marginally outperforms the state-of-the-art on GRID dataset.
Stochastic Talking Face Generation Using Latent Distribution Matching
Nov 21, 2020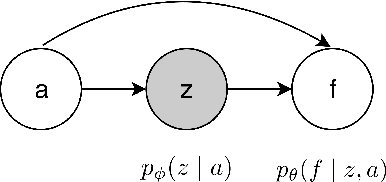
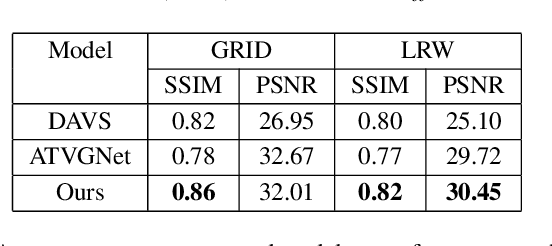
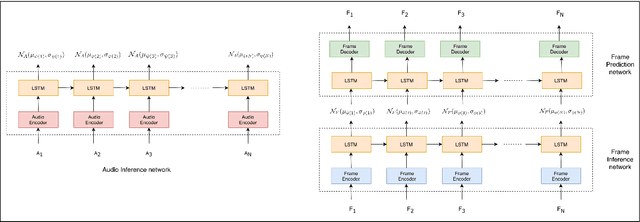
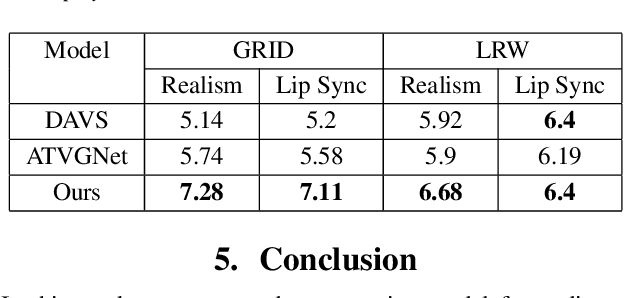
The ability to envisage the visual of a talking face based just on hearing a voice is a unique human capability. There have been a number of works that have solved for this ability recently. We differ from these approaches by enabling a variety of talking face generations based on single audio input. Indeed, just having the ability to generate a single talking face would make a system almost robotic in nature. In contrast, our unsupervised stochastic audio-to-video generation model allows for diverse generations from a single audio input. Particularly, we present an unsupervised stochastic audio-to-video generation model that can capture multiple modes of the video distribution. We ensure that all the diverse generations are plausible. We do so through a principled multi-modal variational autoencoder framework. We demonstrate its efficacy on the challenging LRW and GRID datasets and demonstrate performance better than the baseline, while having the ability to generate multiple diverse lip synchronized videos.
Speech Prediction in Silent Videos using Variational Autoencoders
Nov 14, 2020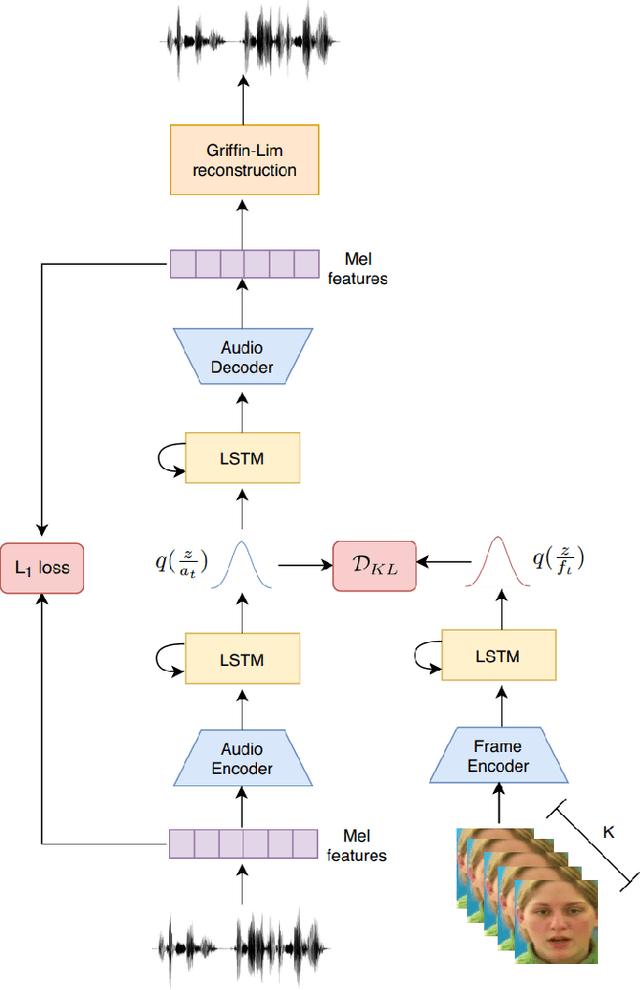
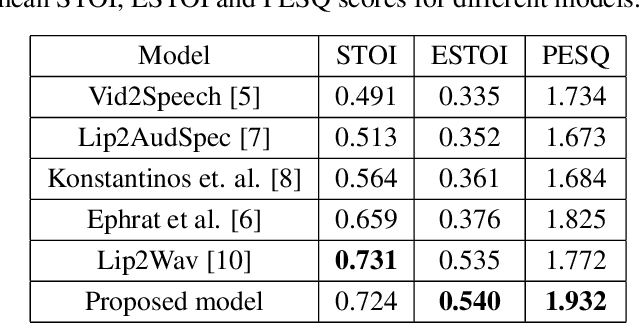
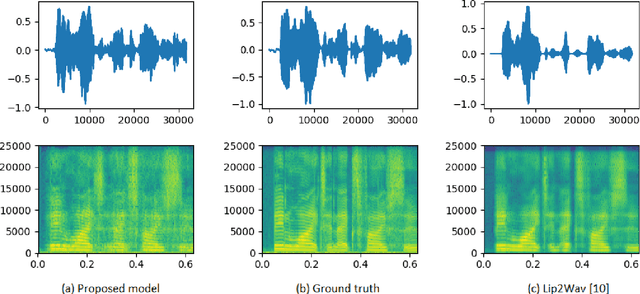
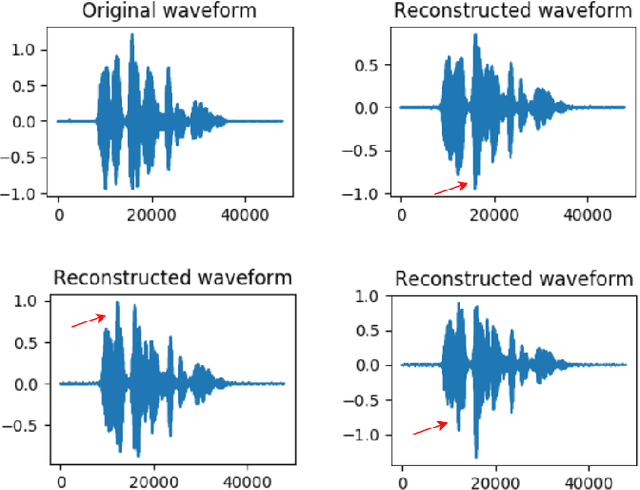
Understanding the relationship between the auditory and visual signals is crucial for many different applications ranging from computer-generated imagery (CGI) and video editing automation to assisting people with hearing or visual impairments. However, this is challenging since the distribution of both audio and visual modality is inherently multimodal. Therefore, most of the existing methods ignore the multimodal aspect and assume that there only exists a deterministic one-to-one mapping between the two modalities. It can lead to low-quality predictions as the model collapses to optimizing the average behavior rather than learning the full data distributions. In this paper, we present a stochastic model for generating speech in a silent video. The proposed model combines recurrent neural networks and variational deep generative models to learn the auditory signal's conditional distribution given the visual signal. We demonstrate the performance of our model on the GRID dataset based on standard benchmarks.
A Generalized Framework for Autonomous Calibration of Wheeled Mobile Robots
Jan 06, 2020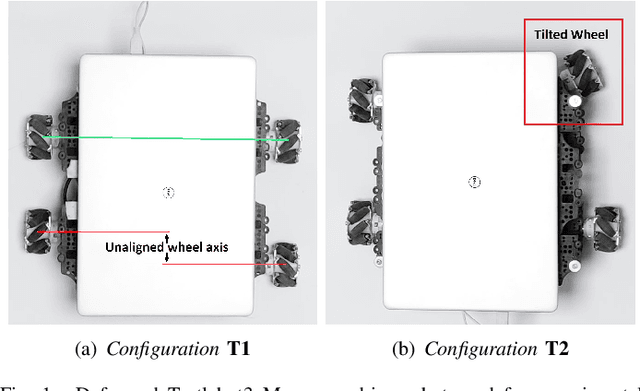
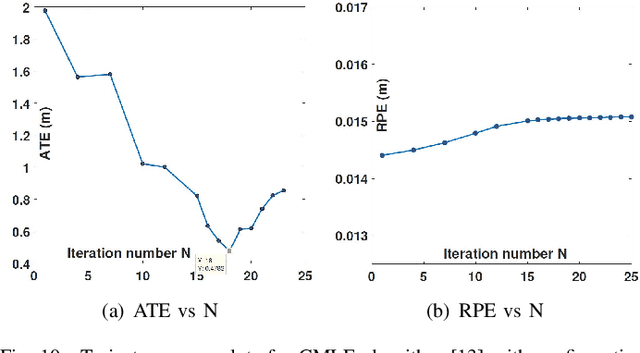
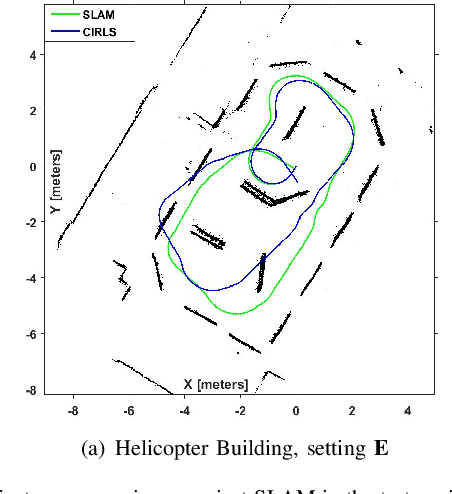
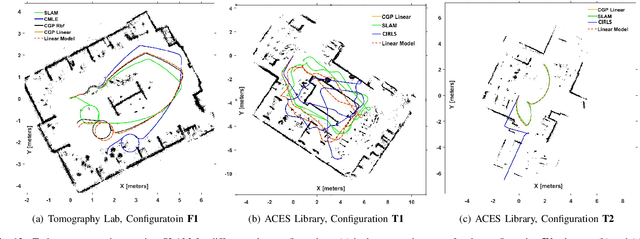
Robotic calibration allows for the fusion of data from multiple sensors such as odometers, cameras, etc., by providing appropriate transformational relationships between the corresponding reference frames. For wheeled robots equipped with exteroceptive sensors, calibration entails learning the motion model of the sensor or the robot in terms of the odometric data, and must generally be performed prior to performing tasks such as simultaneous localization and mapping (SLAM). Within this context, the current trend is to carry out simultaneous calibration of odometry and sensor without the use of any additional hardware. Building upon the existing simultaneous calibration algorithms, we put forth a generalized calibration framework that can not only handle robots operating in 2D with arbitrary or unknown motion models but also handle outliers in an automated manner. We first propose an algorithm based on the alternating minimization framework applicable to two-wheel differential drive. Subsequently, for arbitrary but known drive configurations we put forth an iteratively re-weighted least squares methodology leveraging an intelligent weighing scheme. Different from the existing works, these proposed algorithms require no manual intervention and seamlessly handle outliers that arise due to both systematic and non-systematic errors. Finally, we put forward a novel Gaussian Process-based non-parametric approach for calibrating wheeled robots with arbitrary or unknown drive configurations. Detailed experiments are performed to demonstrate the accuracy, usefulness, and flexibility of the proposed algorithms.
Model Free Calibration of Wheeled Robots Using Gaussian Process
Oct 25, 2019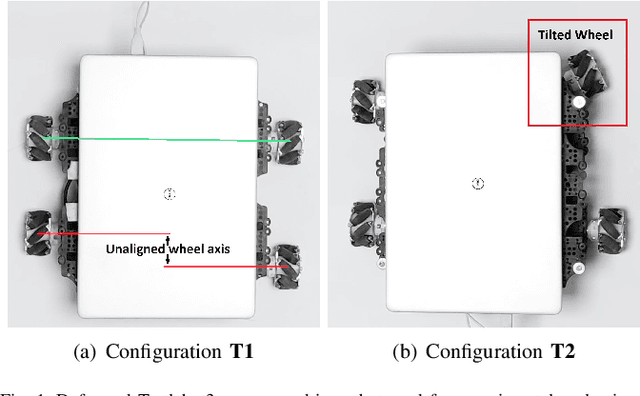
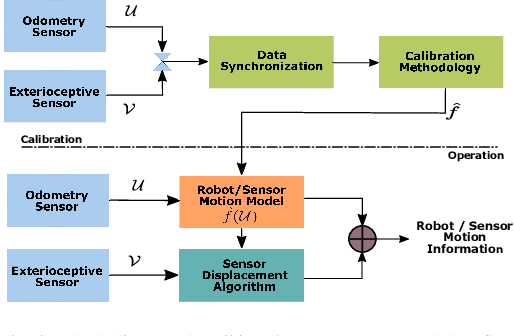
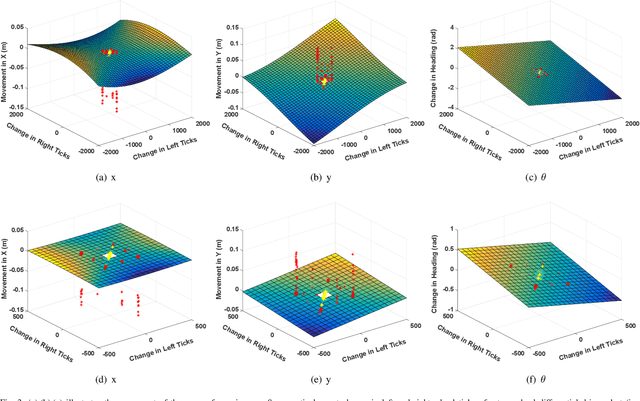

Robotic calibration allows for the fusion of data from multiple sensors such as odometers, cameras, etc., by providing appropriate relationships between the corresponding reference frames. For wheeled robots equipped with camera/lidar along with wheel encoders, calibration entails learning the motion model of the sensor or the robot in terms of the data from the encoders and generally carried out before performing tasks such as simultaneous localization and mapping (SLAM). This work puts forward a novel Gaussian Process-based non-parametric approach for calibrating wheeled robots with arbitrary or unknown drive configurations. The procedure is more general as it learns the entire sensor/robot motion model in terms of odometry measurements. Different from existing non-parametric approaches, our method relies on measurements from the onboard sensors and hence does not require the ground truth information from external motion capture systems. Alternatively, we propose a computationally efficient approach that relies on the linear approximation of the sensor motion model. Finally, we perform experiments to calibrate robots with un-modelled effects to demonstrate the accuracy, usefulness, and flexibility of the proposed approach.