 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Evaluation Models for RAG: Who Detects Hallucinations Best?
Mar 27, 2025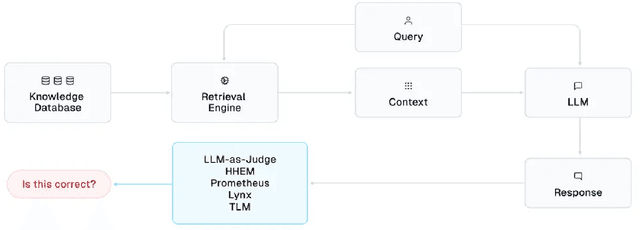
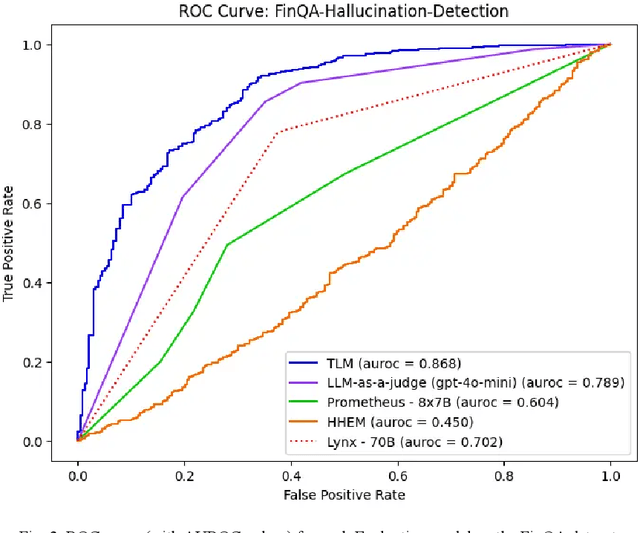
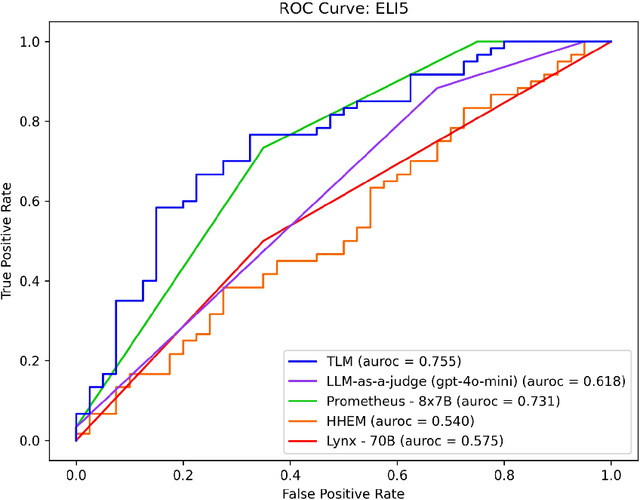
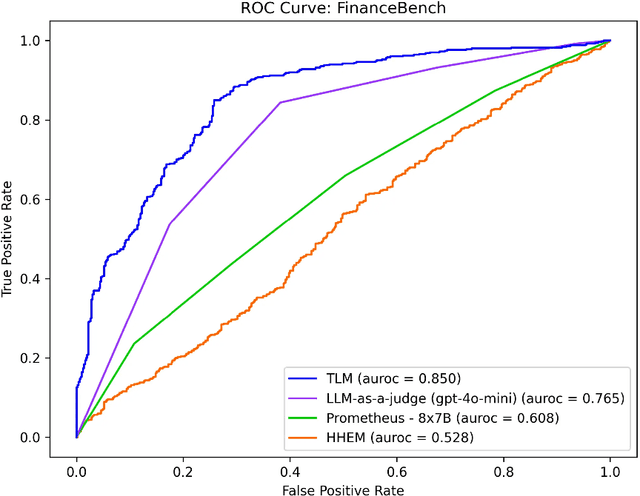
This article surveys Evaluation models to automatically detect hallucinations in Retrieval-Augmented Generation (RAG), and presents a comprehensive benchmark of their performance across six RAG applications. Methods included in our study include: LLM-as-a-Judge, Prometheus, Lynx, the Hughes Hallucination Evaluation Model (HHEM), and the Trustworthy Language Model (TLM). These approaches are all reference-free, requiring no ground-truth answers/labels to catch incorrect LLM responses. Our study reveals that, across diverse RAG applications, some of these approaches consistently detect incorrect RAG responses with high precision/recall.
Stochastic Talking Face Generation Using Latent Distribution Matching
Nov 21, 2020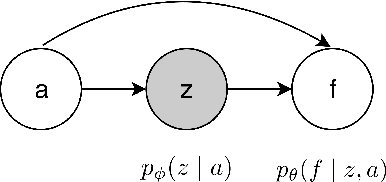
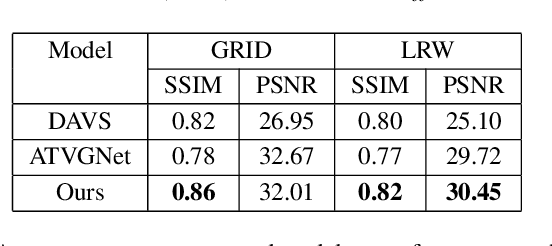
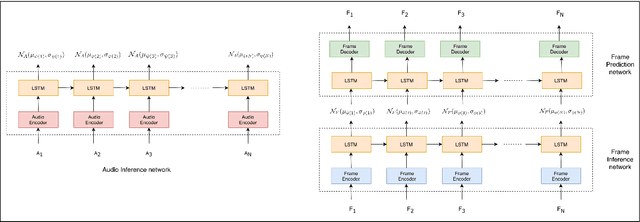
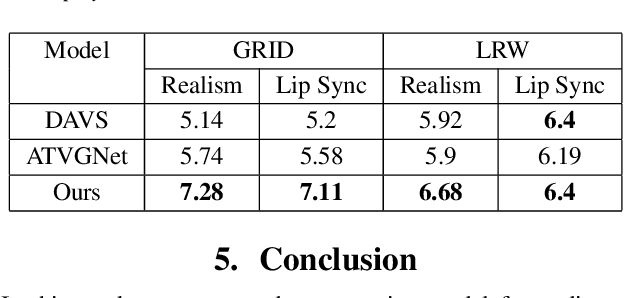
The ability to envisage the visual of a talking face based just on hearing a voice is a unique human capability. There have been a number of works that have solved for this ability recently. We differ from these approaches by enabling a variety of talking face generations based on single audio input. Indeed, just having the ability to generate a single talking face would make a system almost robotic in nature. In contrast, our unsupervised stochastic audio-to-video generation model allows for diverse generations from a single audio input. Particularly, we present an unsupervised stochastic audio-to-video generation model that can capture multiple modes of the video distribution. We ensure that all the diverse generations are plausible. We do so through a principled multi-modal variational autoencoder framework. We demonstrate its efficacy on the challenging LRW and GRID datasets and demonstrate performance better than the baseline, while having the ability to generate multiple diverse lip synchronized videos.
Speech Prediction in Silent Videos using Variational Autoencoders
Nov 14, 2020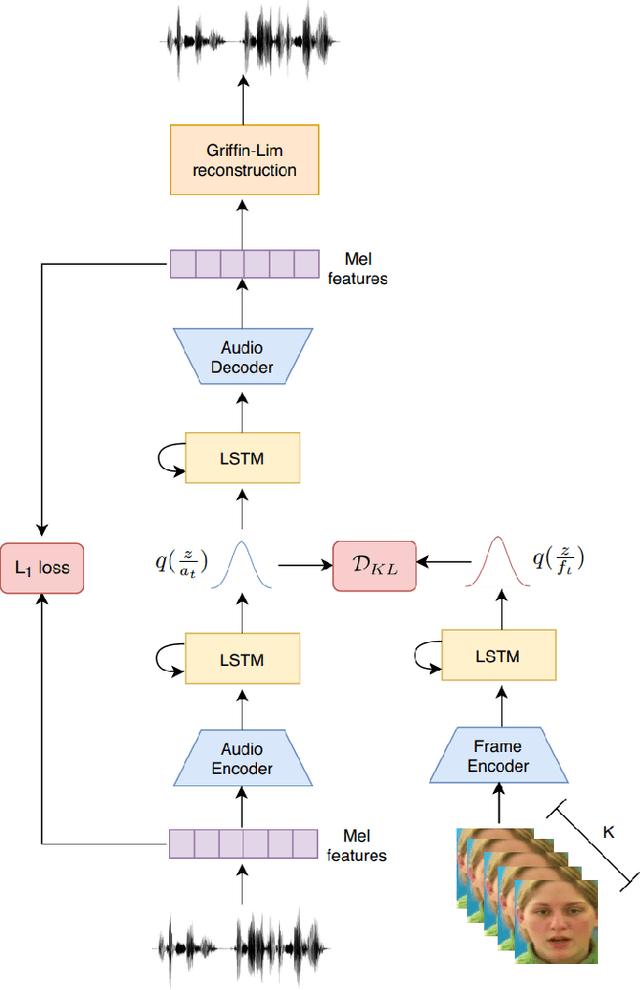
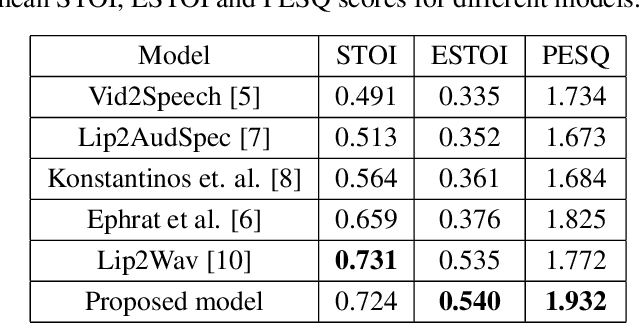
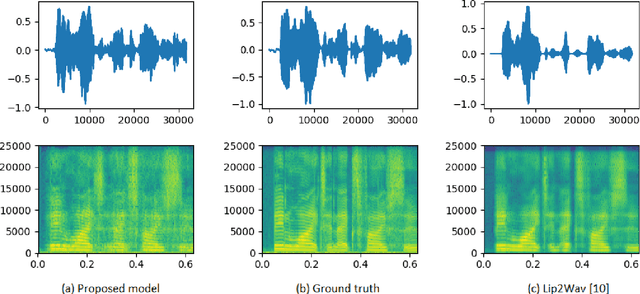
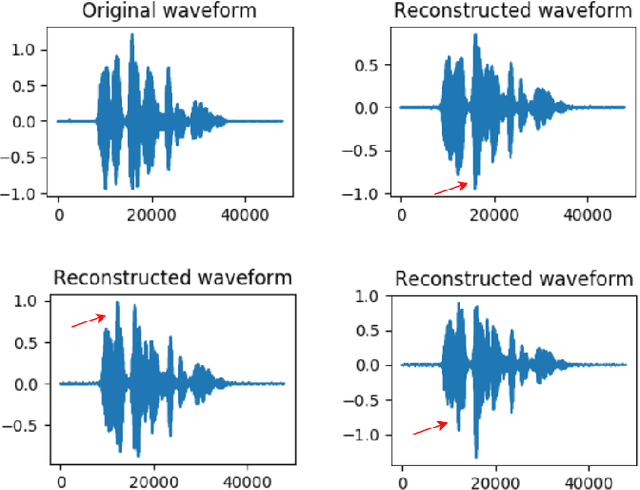
Understanding the relationship between the auditory and visual signals is crucial for many different applications ranging from computer-generated imagery (CGI) and video editing automation to assisting people with hearing or visual impairments. However, this is challenging since the distribution of both audio and visual modality is inherently multimodal. Therefore, most of the existing methods ignore the multimodal aspect and assume that there only exists a deterministic one-to-one mapping between the two modalities. It can lead to low-quality predictions as the model collapses to optimizing the average behavior rather than learning the full data distributions. In this paper, we present a stochastic model for generating speech in a silent video. The proposed model combines recurrent neural networks and variational deep generative models to learn the auditory signal's conditional distribution given the visual signal. We demonstrate the performance of our model on the GRID dataset based on standard benchmarks.
Multilogue-Net: A Context Aware RNN for Multi-modal Emotion Detection and Sentiment Analysis in Conversation
Feb 20, 2020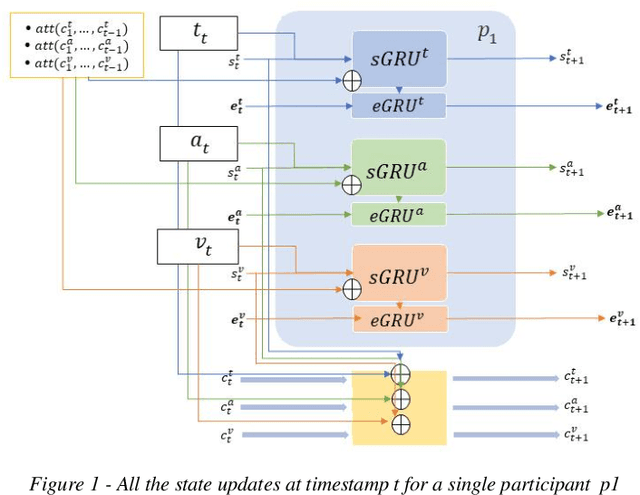
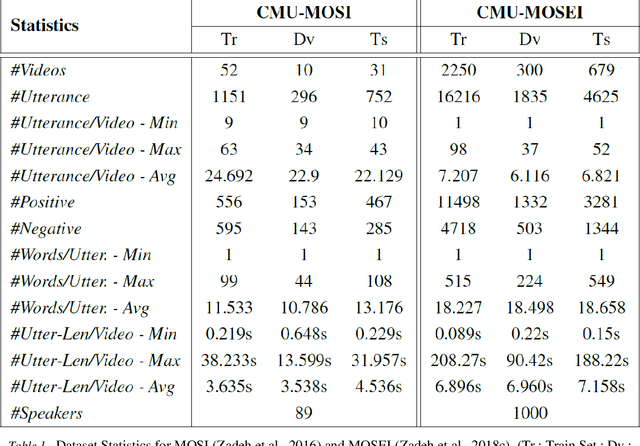
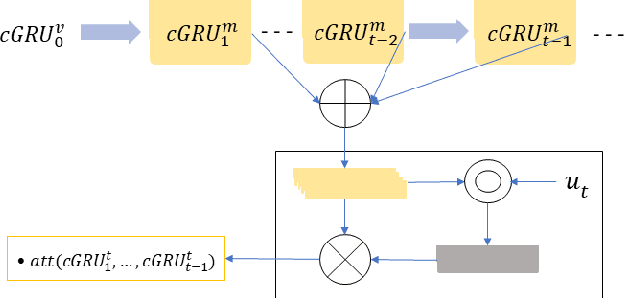

Sentiment Analysis and Emotion Detection in conversation is key in a number of real-world applications, with different applications leveraging different kinds of data to be able to achieve reasonably accurate predictions. Multimodal Emotion Detection and Sentiment Analysis can be particularly useful as applications will be able to use specific subsets of the available modalities, as per their available data, to be able to produce relevant predictions. Current systems dealing with Multimodal functionality fail to leverage and capture the context of the conversation through all modalities, the current speaker and listener(s) in the conversation, and the relevance and relationship between the available modalities through an adequate fusion mechanism. In this paper, we propose a recurrent neural network architecture that attempts to take into account all the mentioned drawbacks, and keeps track of the context of the conversation, interlocutor states, and the emotions conveyed by the speakers in the conversation. Our proposed model out performs the state of the art on two benchmark datasets on a variety of accuracy and regression metrics.