Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Evaluation Models for RAG: Who Detects Hallucinations Best?
Paper and Code
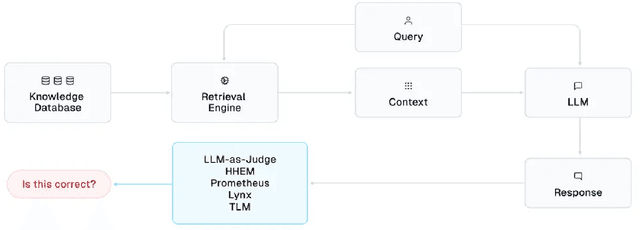
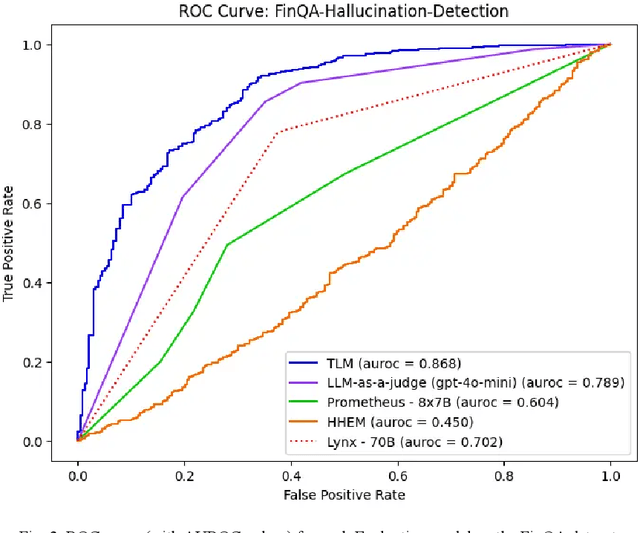
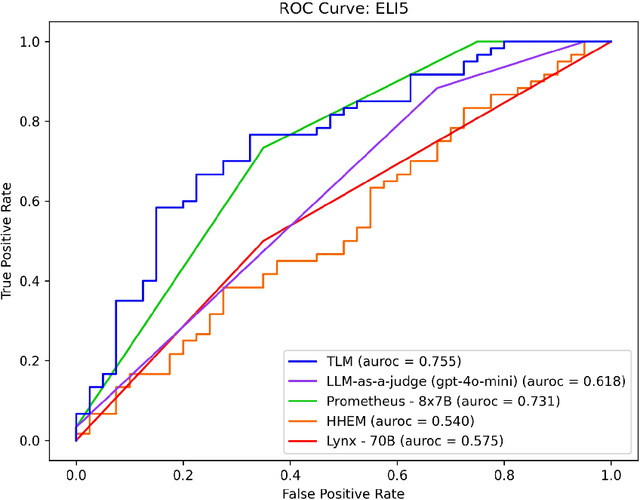
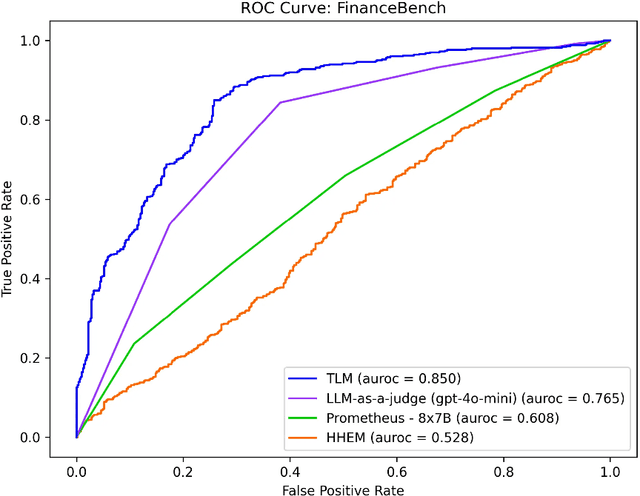
This article surveys Evaluation models to automatically detect hallucinations in Retrieval-Augmented Generation (RAG), and presents a comprehensive benchmark of their performance across six RAG applications. Methods included in our study include: LLM-as-a-Judge, Prometheus, Lynx, the Hughes Hallucination Evaluation Model (HHEM), and the Trustworthy Language Model (TLM). These approaches are all reference-free, requiring no ground-truth answers/labels to catch incorrect LLM responses. Our study reveals that, across diverse RAG applications, some of these approaches consistently detect incorrect RAG responses with high precision/recall.
* 11 pages, 8 figures
View paper on