 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Speaker-specific Lip-to-Speech Generation
Jun 04, 2022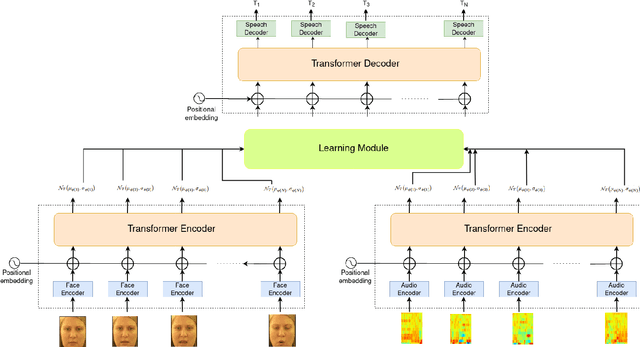
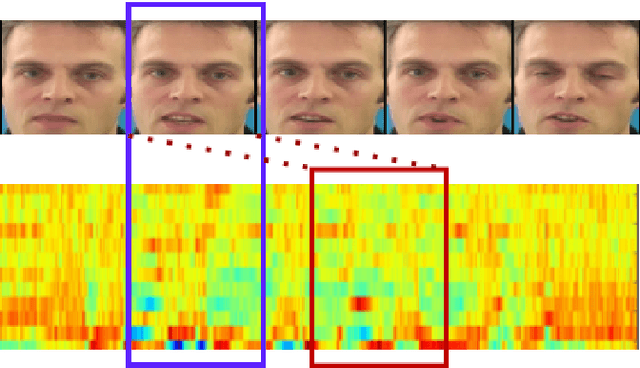
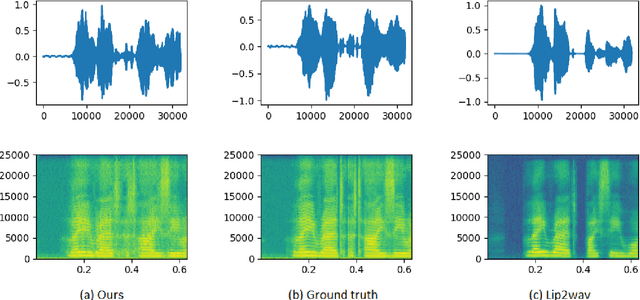
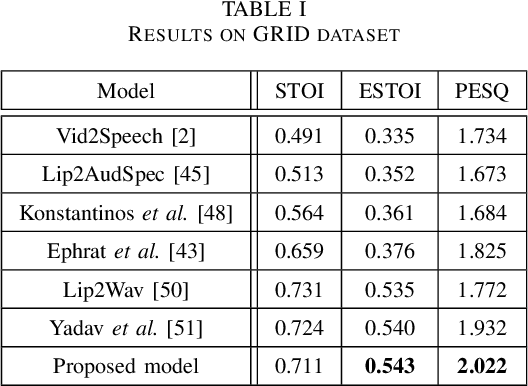
Understanding the lip movement and inferring the speech from it is notoriously difficult for the common person. The task of accurate lip-reading gets help from various cues of the speaker and its contextual or environmental setting. Every speaker has a different accent and speaking style, which can be inferred from their visual and speech features. This work aims to understand the correlation/mapping between speech and the sequence of lip movement of individual speakers in an unconstrained and large vocabulary. We model the frame sequence as a prior to the transformer in an auto-encoder setting and learned a joint embedding that exploits temporal properties of both audio and video. We learn temporal synchronization using deep metric learning, which guides the decoder to generate speech in sync with input lip movements. The predictive posterior thus gives us the generated speech in speaker speaking style. We have trained our model on the Grid and Lip2Wav Chemistry lecture dataset to evaluate single speaker natural speech generation tasks from lip movement in an unconstrained natural setting. Extensive evaluation using various qualitative and quantitative metrics with human evaluation also shows that our method outperforms the Lip2Wav Chemistry dataset(large vocabulary in an unconstrained setting) by a good margin across almost all evaluation metrics and marginally outperforms the state-of-the-art on GRID dataset.
Minimizing Supervision in Multi-label Categorization
May 26, 2020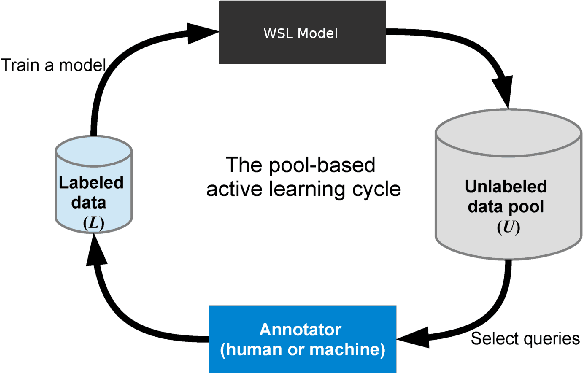

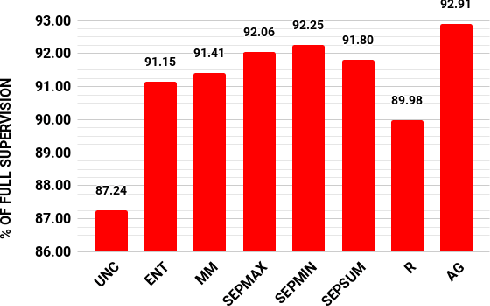
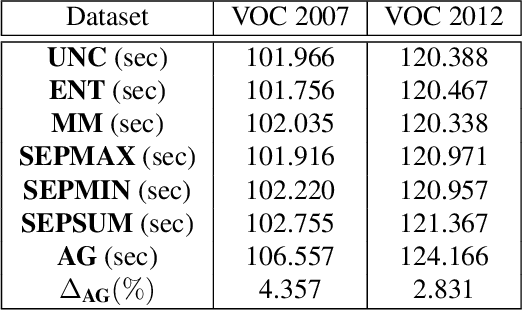
Multiple categories of objects are present in most images. Treating this as a multi-class classification is not justified. We treat this as a multi-label classification problem. In this paper, we further aim to minimize the supervision required for providing supervision in multi-label classification. Specifically, we investigate an effective class of approaches that associate a weak localization with each category either in terms of the bounding box or segmentation mask. Doing so improves the accuracy of multi-label categorization. The approach we adopt is one of active learning, i.e., incrementally selecting a set of samples that need supervision based on the current model, obtaining supervision for these samples, retraining the model with the additional set of supervised samples and proceeding again to select the next set of samples. A crucial concern is the choice of the set of samples. In doing so, we provide a novel insight, and no specific measure succeeds in obtaining a consistently improved selection criterion. We, therefore, provide a selection criterion that consistently improves the overall baseline criterion by choosing the top k set of samples for a varied set of criteria. Using this criterion, we are able to show that we can retain more than 98% of the fully supervised performance with just 20% of samples (and more than 96% using 10%) of the dataset on PASCAL VOC 2007 and 2012. Also, our proposed approach consistently outperforms all other baseline metrics for all benchmark datasets and model combinations.
Cooperative Initialization based Deep Neural Network Training
Jan 05, 2020



Researchers have proposed various activation functions. These activation functions help the deep network to learn non-linear behavior with a significant effect on training dynamics and task performance. The performance of these activations also depends on the initial state of the weight parameters, i.e., different initial state leads to a difference in the performance of a network. In this paper, we have proposed a cooperative initialization for training the deep network using ReLU activation function to improve the network performance. Our approach uses multiple activation functions in the initial few epochs for the update of all sets of weight parameters while training the network. These activation functions cooperate to overcome their drawbacks in the update of weight parameters, which in effect learn better "feature representation" and boost the network performance later. Cooperative initialization based training also helps in reducing the overfitting problem and does not increase the number of parameters, inference (test) time in the final model while improving the performance. Experiments show that our approach outperforms various baselines and, at the same time, performs well over various tasks such as classification and detection. The Top-1 classification accuracy of the model trained using our approach improves by 2.8% for VGG-16 and 2.1% for ResNet-56 on CIFAR-100 dataset.