 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Based Knowledge Transfer Under State-Action Dimension Mismatch
Paper and Code

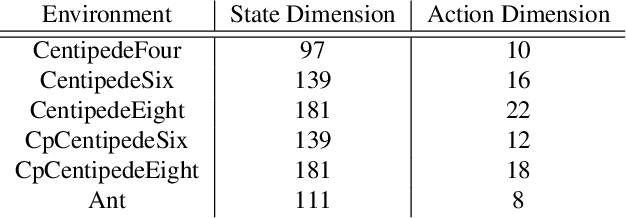


Deep reinforcement learning (RL) algorithms have achieved great success on a wide variety of sequential decision-making tasks. However, many of these algorithms suffer from high sample complexity when learning from scratch using environmental rewards, due to issues such as credit-assignment and high-variance gradients, among others. Transfer learning, in which knowledge gained on a source task is applied to more efficiently learn a different but related target task, is a promising approach to improve the sample complexity in RL. Prior work has considered using pre-trained teacher policies to enhance the learning of the student policy, albeit with the constraint that the teacher and the student MDPs share the state-space or the action-space. In this paper, we propose a new framework for transfer learning where the teacher and the student can have arbitrarily different state- and action-spaces. To handle this mismatch, we produce embeddings which can systematically extract knowledge from the teacher policy and value networks, and blend it into the student networks. To train the embeddings, we use a task-aligned loss and show that the representations could be enriched further by adding a mutual information loss. Using a set of challenging simulated robotic locomotion tasks involving many-legged centipedes, we demonstrate successful transfer learning in situations when the teacher and student have different state- and action-spaces.