 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Learning for Text Classification by Layer Partitioning
Paper and Code
Nov 26, 2019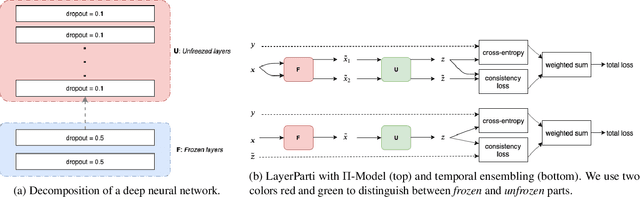
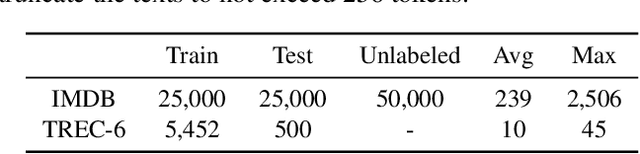
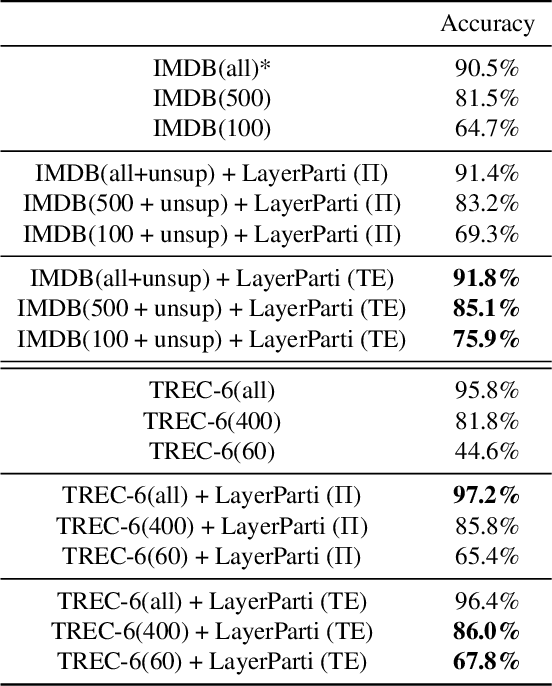
Most recent neural semi-supervised learning algorithms rely on adding small perturbation to either the input vectors or their representations. These methods have been successful on computer vision tasks as the images form a continuous manifold, but are not appropriate for discrete input such as sentence. To adapt these methods to text input, we propose to decompose a neural network $M$ into two components $F$ and $U$ so that $M = U\circ F$. The layers in $F$ are then frozen and only the layers in $U$ will be updated during most time of the training. In this way, $F$ serves as a feature extractor that maps the input to high-level representation and adds systematical noise using dropout. We can then train $U$ using any state-of-the-art SSL algorithms such as $\Pi$-model, temporal ensembling, mean teacher, etc. Furthermore, this gradually unfreezing schedule also prevents a pretrained model from catastrophic forgetting. The experimental results demonstrate that our approach provides improvements when compared to state of the art methods especially on short texts.