 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation in Document Retrieval
Paper and Code
Nov 11, 2019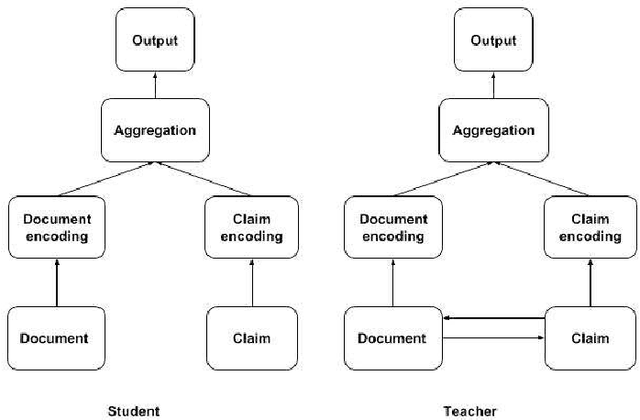
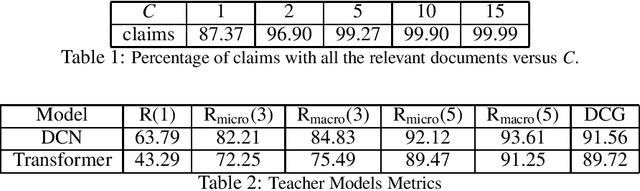

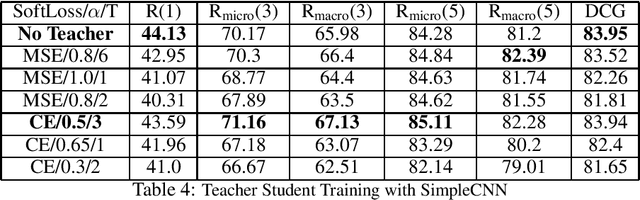
Complex deep learning models now achieve state of the art performance for many document retrieval tasks. The best models process the query or claim jointly with the document. However for fast scalable search it is desirable to have document embeddings which are independent of the claim. In this paper we show that knowledge distillation can be used to encourage a model that generates claim independent document encodings to mimic the behavior of a more complex model which generates claim dependent encodings. We explore this approach in document retrieval for a fact extraction and verification task. We show that by using the soft labels from a complex cross attention teacher model, the performance of claim independent student LSTM or CNN models is improved across all the ranking metrics. The student models we use are 12x faster in runtime and 20x smaller in number of parameters than the teacher