 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Shallow Fusion for RNN-T Personalization
Paper and Code
Nov 16, 2020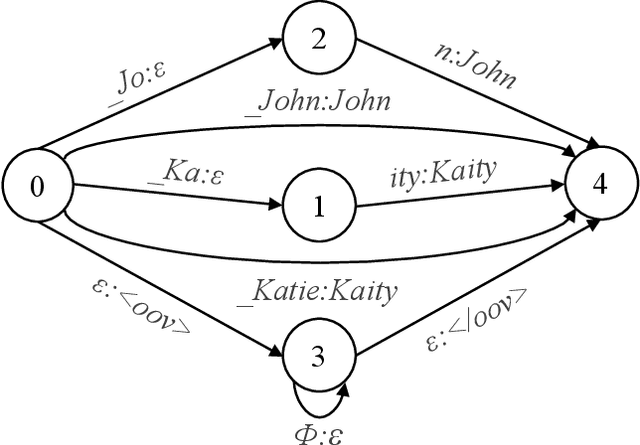
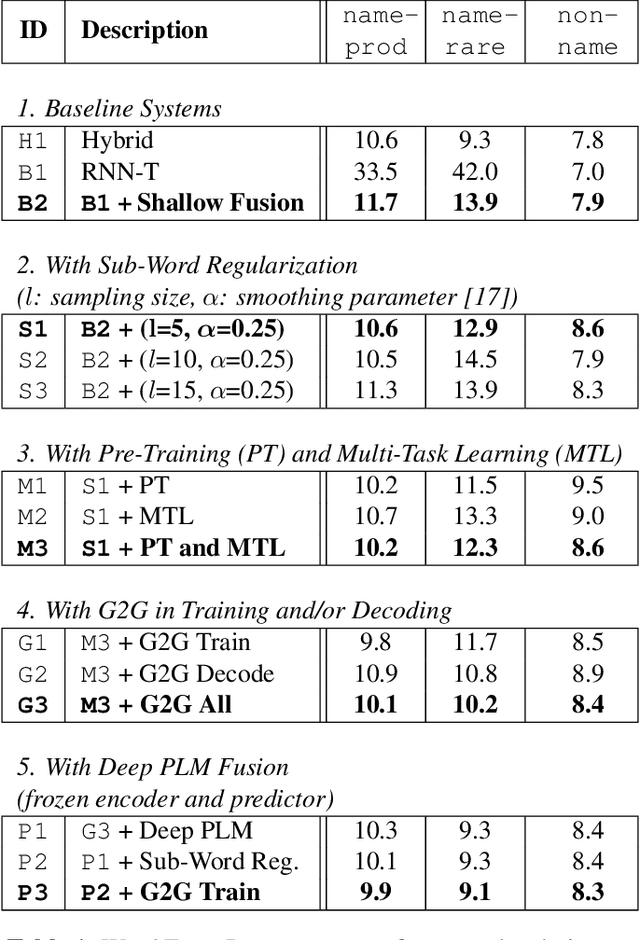
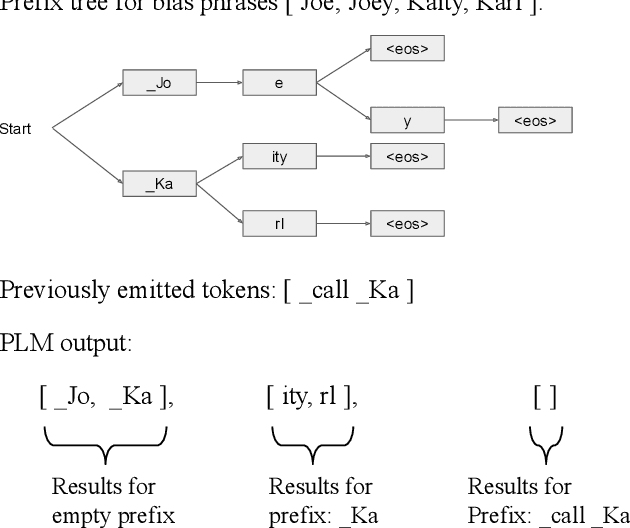
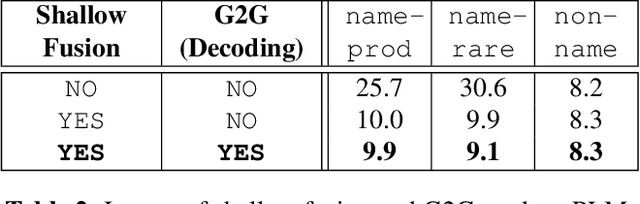
End-to-end models in general, and Recurrent Neural Network Transducer (RNN-T) in particular, have gained significant traction in the automatic speech recognition community in the last few years due to their simplicity, compactness, and excellent performance on generic transcription tasks. However, these models are more challenging to personalize compared to traditional hybrid systems due to the lack of external language models and difficulties in recognizing rare long-tail words, specifically entity names. In this work, we present novel techniques to improve RNN-T's ability to model rare WordPieces, infuse extra information into the encoder, enable the use of alternative graphemic pronunciations, and perform deep fusion with personalized language models for more robust biasing. We show that these combined techniques result in 15.4%-34.5% relative Word Error Rate improvement compared to a strong RNN-T baseline which uses shallow fusion and text-to-speech augmentation. Our work helps push the boundary of RNN-T personalization and close the gap with hybrid systems on use cases where biasing and entity recognition are crucial.