Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Paper and Code
Oct 29, 2020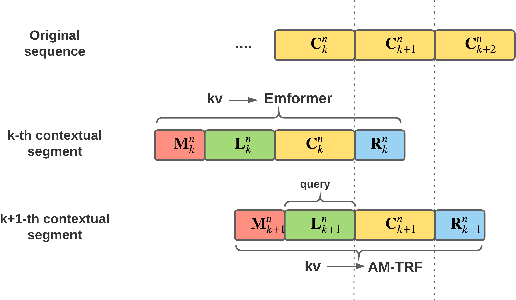
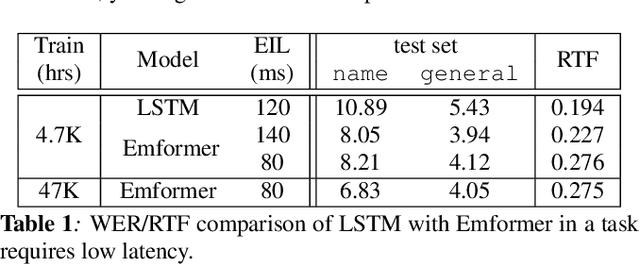
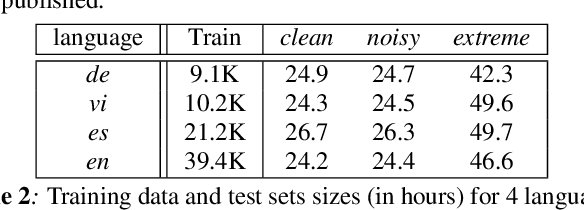
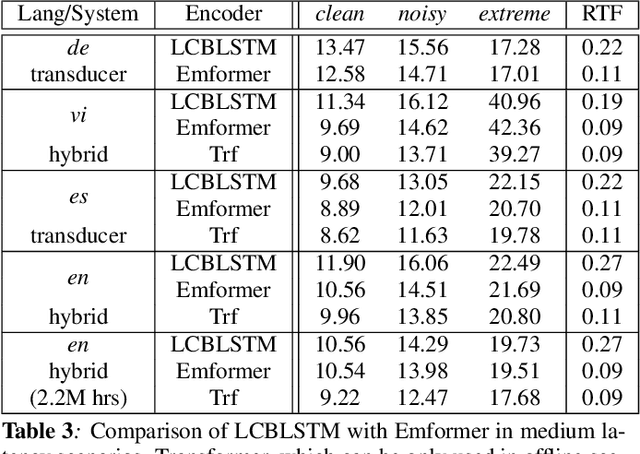
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.
* submitted to ICASSP2021
View paper on