 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Time-Frequency Representation Discriminators for High-Fidelity Vocoder
Paper and Code
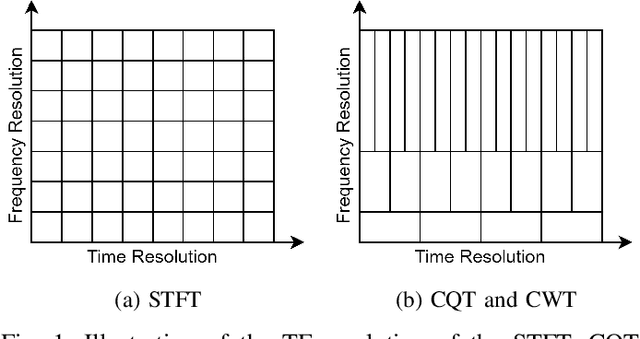
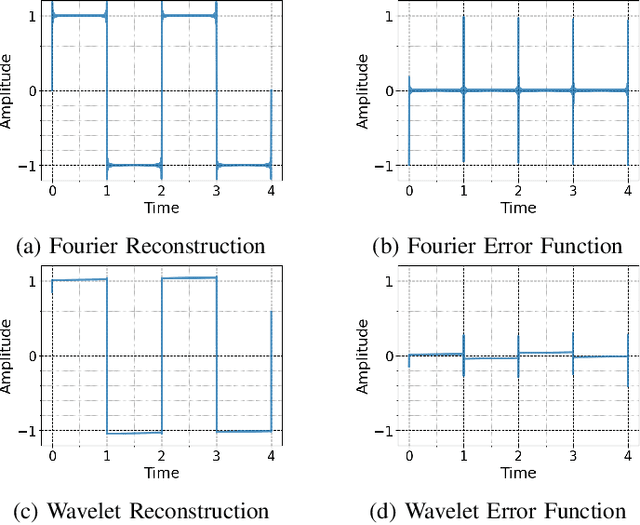
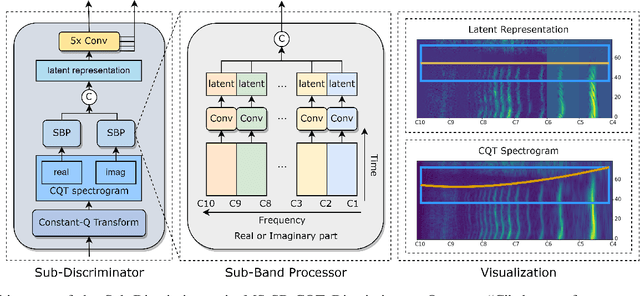
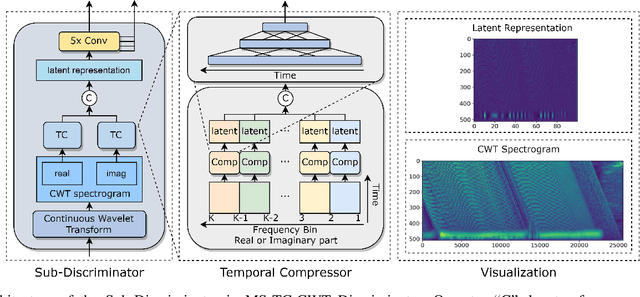
Generative Adversarial Network (GAN) based vocoders are superior in both inference speed and synthesis quality when reconstructing an audible waveform from an acoustic representation. This study focuses on improving the discriminator for GAN-based vocoders. Most existing Time-Frequency Representation (TFR)-based discriminators are rooted in Short-Time Fourier Transform (STFT), which owns a constant Time-Frequency (TF) resolution, linearly scaled center frequencies, and a fixed decomposition basis, making it incompatible with signals like singing voices that require dynamic attention for different frequency bands and different time intervals. Motivated by that, we propose a Multi-Scale Sub-Band Constant-Q Transform CQT (MS-SB-CQT) discriminator and a Multi-Scale Temporal-Compressed Continuous Wavelet Transform CWT (MS-TC-CWT) discriminator. Both CQT and CWT have a dynamic TF resolution for different frequency bands. In contrast, CQT has a better modeling ability in pitch information, and CWT has a better modeling ability in short-time transients. Experiments conducted on both speech and singing voices confirm the effectiveness of our proposed discriminators. Moreover, the STFT, CQT, and CWT-based discriminators can be used jointly for better performance. The proposed discriminators can boost the synthesis quality of various state-of-the-art GAN-based vocoders, including HiFi-GAN, BigVGAN, and APNet.