 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetic and Prosody-aware Self-supervised Learning Approach for Non-native Fluency Scoring
May 19, 2023Speech fluency/disfluency can be evaluated by analyzing a range of phonetic and prosodic features. Deep neural networks are commonly trained to map fluency-related features into the human scores. However, the effectiveness of deep learning-based models is constrained by the limited amount of labeled training samples. To address this, we introduce a self-supervised learning (SSL) approach that takes into account phonetic and prosody awareness for fluency scoring. Specifically, we first pre-train the model using a reconstruction loss function, by masking phones and their durations jointly on a large amount of unlabeled speech and text prompts. We then fine-tune the pre-trained model using human-annotated scoring data. Our experimental results, conducted on datasets such as Speechocean762 and our non-native datasets, show that our proposed method outperforms the baseline systems in terms of Pearson correlation coefficients (PCC). Moreover, we also conduct an ablation study to better understand the contribution of phonetic and prosody factors during the pre-training stage.
Improving Non-native Word-level Pronunciation Scoring with Phone-level Mixup Data Augmentation and Multi-source Information
Mar 01, 2022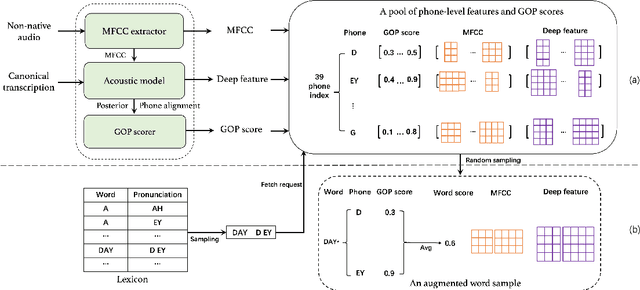

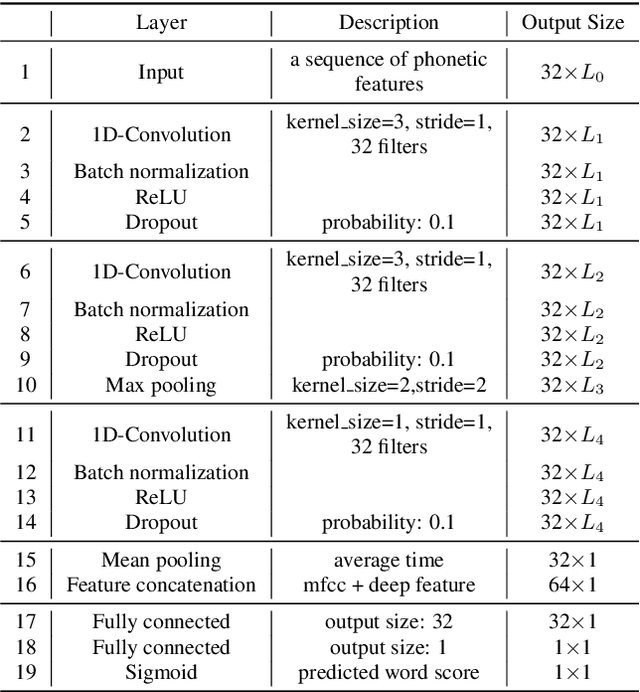
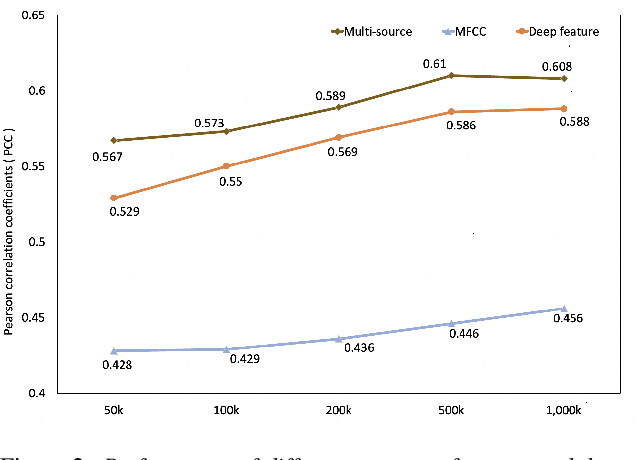
Deep learning-based pronunciation scoring models highly rely on the availability of the annotated non-native data, which is costly and has scalability issues. To deal with the data scarcity problem, data augmentation is commonly used for model pretraining. In this paper, we propose a phone-level mixup, a simple yet effective data augmentation method, to improve the performance of word-level pronunciation scoring. Specifically, given a phoneme sequence from lexicon, the artificial augmented word sample can be generated by randomly sampling from the corresponding phone-level features in training data, while the word score is the average of their GOP scores. Benefit from the arbitrary phone-level combination, the mixup is able to generate any word with various pronunciation scores. Moreover, we utilize multi-source information (e.g., MFCC and deep features) to further improve the scoring system performance. The experiments conducted on the Speechocean762 show that the proposed system outperforms the baseline by adding the mixup data for pretraining, with Pearson correlation coefficients (PCC) increasing from 0.567 to 0.61. The results also indicate that proposed method achieves similar performance by using 1/10 unlabeled data of baseline. In addition, the experimental results also demonstrate the efficiency of our proposed multi-source approach.