 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetic and Prosody-aware Self-supervised Learning Approach for Non-native Fluency Scoring
May 19, 2023Speech fluency/disfluency can be evaluated by analyzing a range of phonetic and prosodic features. Deep neural networks are commonly trained to map fluency-related features into the human scores. However, the effectiveness of deep learning-based models is constrained by the limited amount of labeled training samples. To address this, we introduce a self-supervised learning (SSL) approach that takes into account phonetic and prosody awareness for fluency scoring. Specifically, we first pre-train the model using a reconstruction loss function, by masking phones and their durations jointly on a large amount of unlabeled speech and text prompts. We then fine-tune the pre-trained model using human-annotated scoring data. Our experimental results, conducted on datasets such as Speechocean762 and our non-native datasets, show that our proposed method outperforms the baseline systems in terms of Pearson correlation coefficients (PCC). Moreover, we also conduct an ablation study to better understand the contribution of phonetic and prosody factors during the pre-training stage.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023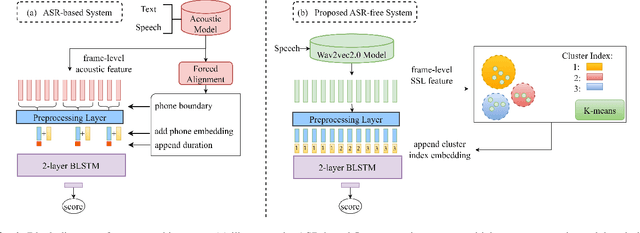
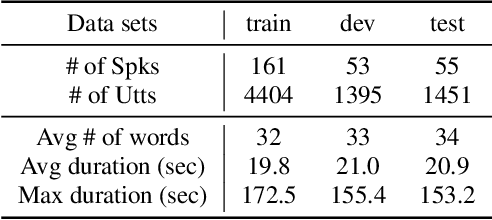
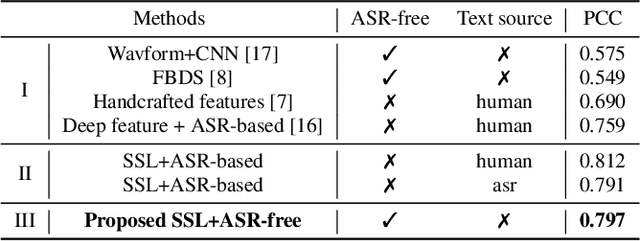
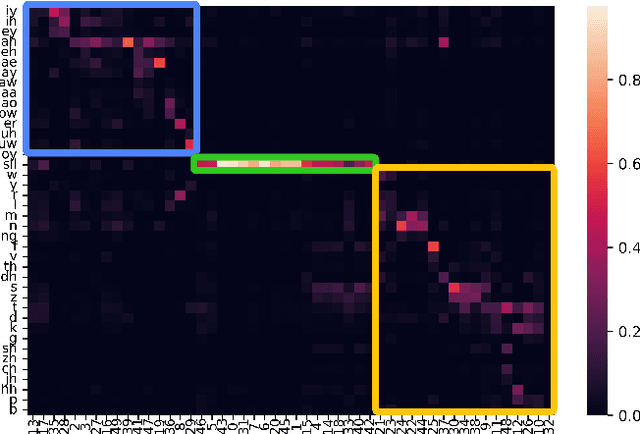
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
Leveraging phone-level linguistic-acoustic similarity for utterance-level pronunciation scoring
Mar 13, 2023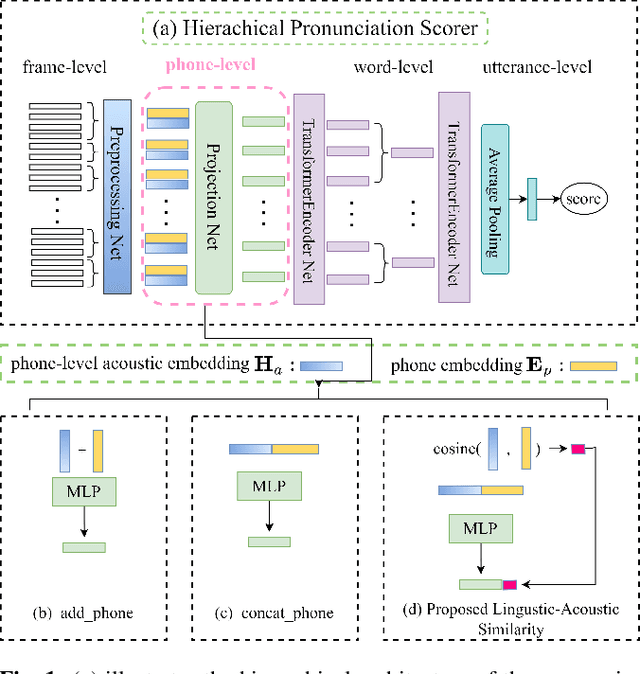
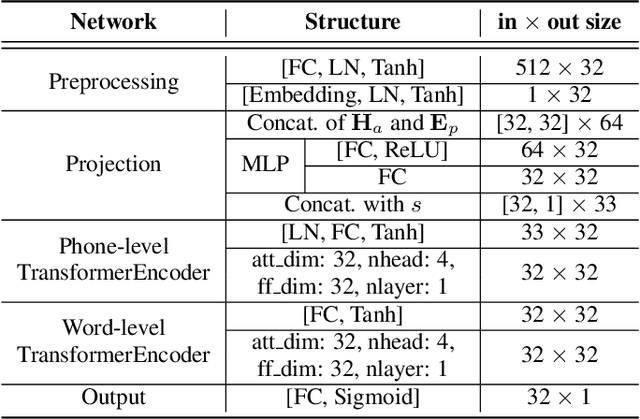
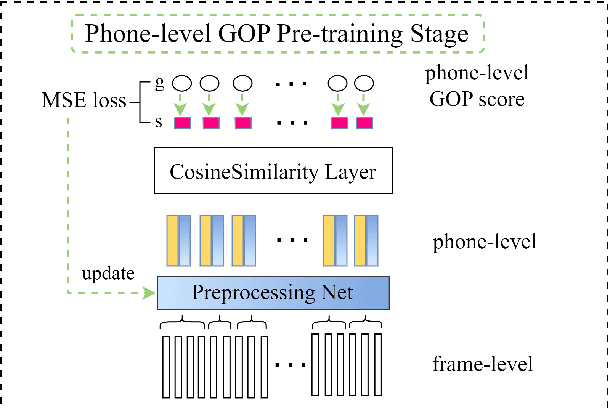
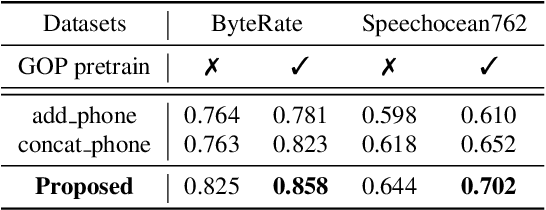
Recent studies on pronunciation scoring have explored the effect of introducing phone embeddings as reference pronunciation, but mostly in an implicit manner, i.e., addition or concatenation of reference phone embedding and actual pronunciation of the target phone as the phone-level pronunciation quality representation. In this paper, we propose to use linguistic-acoustic similarity to explicitly measure the deviation of non-native production from its native reference for pronunciation assessment. Specifically, the deviation is first estimated by the cosine similarity between reference phone embedding and corresponding acoustic embedding. Next, a phone-level Goodness of pronunciation (GOP) pre-training stage is introduced to guide this similarity-based learning for better initialization of the aforementioned two embeddings. Finally, a transformer-based hierarchical pronunciation scorer is used to map a sequence of phone embeddings, acoustic embeddings along with their similarity measures to predict the final utterance-level score. Experimental results on the non-native databases suggest that the proposed system significantly outperforms the baselines, where the acoustic and phone embeddings are simply added or concatenated. A further examination shows that the phone embeddings learned in the proposed approach are able to capture linguistic-acoustic attributes of native pronunciation as reference.