 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARVEL: A Decoupled Model-driven Approach for Efficiently Mapping Convolutions on Spatial DNN Accelerators
Feb 18, 2020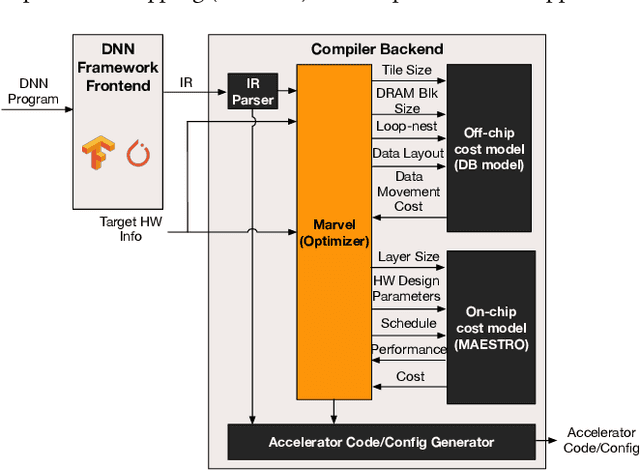
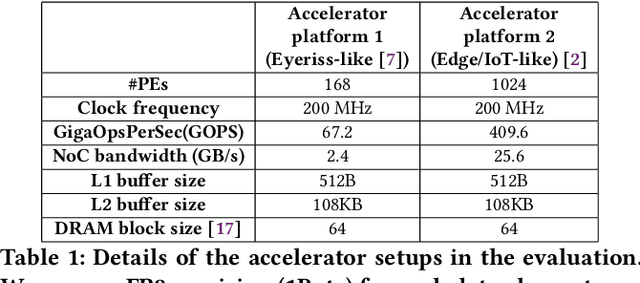
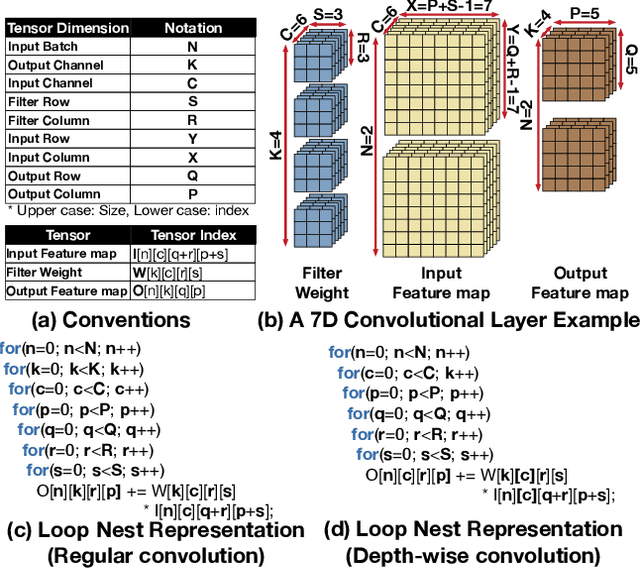
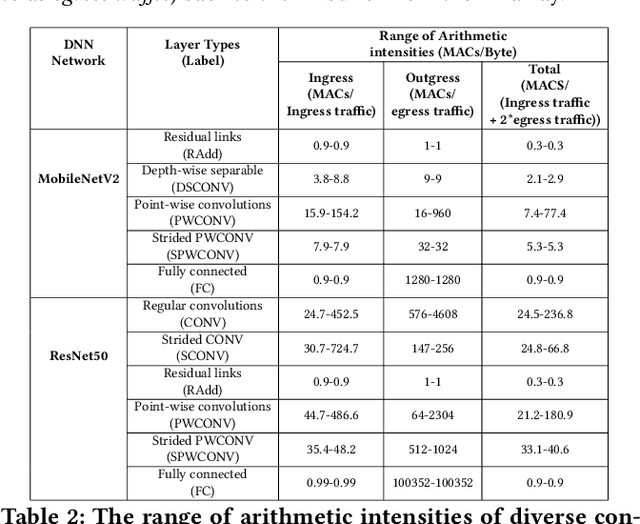
The efficiency of a spatial DNN accelerator depends heavily on the compiler's ability to generate optimized mappings for a given DNN's operators (layers) on to the accelerator's compute and memory resources. Searching for the optimal mapping is challenging because of a massive space of possible data-layouts and loop transformations for the DNN layers. For example, there are over 10^19 valid mappings for a single convolution layer on average for mapping ResNet50 and MobileNetV2 on a representative DNN edge accelerator. This challenge gets exacerbated with new layer types (e.g., depth-wise and point-wise convolutions) and diverse hardware accelerator configurations. To address this challenge, we propose a decoupled off-chip/on-chip approach that decomposes the mapping space into off-chip and on-chip subspaces, and first optimizes the off-chip subspace followed by the on-chip subspace. The motivation for this decomposition is to dramatically reduce the size of the search space, and to also prioritize the optimization of off-chip data movement, which is 2-3 orders of magnitude more compared to the on-chip data movement. We introduce {\em Marvel}, which implements the above approach by leveraging two cost models to explore the two subspaces -- a classical distinct-block (DB) locality cost model for the off-chip subspace, and a state-of-the-art DNN accelerator behavioral cost model, MAESTRO, for the on-chip subspace. Our approach also considers dimension permutation, a form of data-layouts, in the mapping space formulation along with the loop transformations.