 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Kalman Filter based State Estimation and Height Control in Hopping Robots
Aug 21, 2024Quadrotor-based multimodal hopping and flying locomotion significantly improves efficiency and operation time as compared to purely flying systems. However, effective control necessitates continuous estimation of the vertical states. A single hopping state estimator has been shown (Kang 2024), in which two vertical states (position, acceleration) are measured and only velocity is estimated using a moving horizon estimation and visual inertial odometry at 200 Hz. This technique requires complex sensors (IMU, lidar, depth camera, contact force sensor), and computationally intensive calculations (12-core, 5 GHz processor), for a maximum hop height of $\sim$0.6 m at 3.65 kg. Here we show a trained Kalman filter based hopping vertical state estimator (HVSE), requiring only vertical acceleration measurements. Our results show the HVSE can estimate more states (position, velocity) with a mean-absolute-error in the hop apex ratio (height error/ground truth) of 12.5\%, running $\sim$4.2x faster (840 Hz) on a substantially less powerful processor (dual-core 240 MHz) with over $\sim$6.7x the hopping height (4.02 m) at 20\% of the mass (672 g). The presented general HVSE, and training procedure are broadly applicable to jumping, hopping, and legged robots across a wide range of sizes and hopping heights.
Design and Control of an Energy Accumulative Hopping Robot
Dec 13, 2023Jumping and hopping locomotion are efficient means of traversing unstructured rugged terrain with the former being the focus of roboticists. This focus has led to significant performance and understanding in jumping robots but with limited practical applications as they require significant time between jumps to store energy, thus relegating jumping to a secondary role in locomotion. Hopping locomotion, however, can preserve and transfer energy to subsequent hops without long energy storage periods. Therefore, hopping has the potential to be far more energy efficient and agile than jumping. However, to date, only a single untethered hopping robot exists with limited payload and hopping heights (< 1 meter). This is due to the added design and control complexity inherent in the requirements to input energy during dynamic locomotion and control the orientation of the system throughout the hopping cycle, resulting in low energy input and control torques; a redevelopment from basic principles is necessary to advance the capabilities of hopping robots. Here we report hopping robot design principles for efficient and robust systems with high energy input and control torques that are validated through analytical, simulation, and experimental results. The resulting robot (MultiMo-MHR) can hop nearly 4 meters (> 6 times the current state-of-the-art); and is only limited by the impact mechanics and not energy input. The results also directly contradict a recent work that concluded hopping with aerodynamic energy input would be less efficient than flight for hops greater than 0.4 meters.
Musical Chair: Efficient Real-Time Recognition Using Collaborative IoT Devices
Mar 21, 2018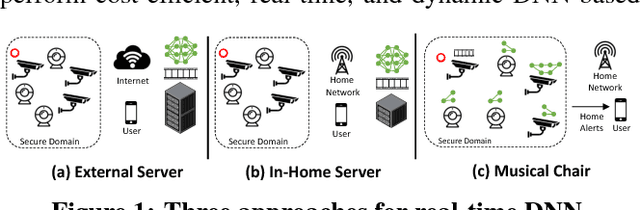

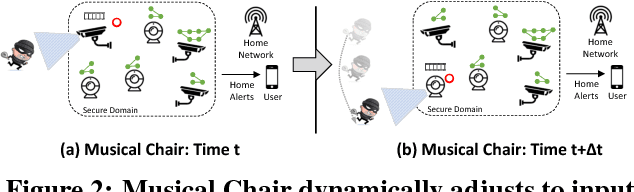

The prevalence of Internet of things (IoT) devices and abundance of sensor data has created an increase in real-time data processing such as recognition of speech, image, and video. While currently such processes are offloaded to the computationally powerful cloud system, a localized and distributed approach is desirable because (i) it preserves the privacy of users and (ii) it omits the dependency on cloud services. However, IoT networks are usually composed of resource-constrained devices, and a single device is not powerful enough to process real-time data. To overcome this challenge, we examine data and model parallelism for such devices in the context of deep neural networks. We propose Musical Chair to enable efficient, localized, and dynamic real-time recognition by harvesting the aggregated computational power from the resource-constrained devices in the same IoT network as input sensors. Musical chair adapts to the availability of computing devices at runtime and adjusts to the inherit dynamics of IoT networks. To demonstrate Musical Chair, on a network of Raspberry PIs (up to 12) each connected to a camera, we implement a state-of-the-art action recognition model for videos and two recognition models for images. Compared to the Tegra TX2, an embedded low-power platform with a six-core CPU and a GPU, our distributed action recognition system achieves not only similar energy consumption but also twice the performance of the TX2. Furthermore, in image recognition, Musical Chair achieves similar performance and saves dynamic energy.