 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMustafar: Promoting Unstructured Sparsity for KV Cache Pruning in LLM Inference
May 28, 2025We demonstrate that unstructured sparsity significantly improves KV cache compression for LLMs, enabling sparsity levels up to 70% without compromising accuracy or requiring fine-tuning. We conduct a systematic exploration of pruning strategies and find per-token magnitude-based pruning as highly effective for both Key and Value caches under unstructured sparsity, surpassing prior structured pruning schemes. The Key cache benefits from prominent outlier elements, while the Value cache surprisingly benefits from a simple magnitude-based pruning despite its uniform distribution. KV cache size is the major bottleneck in decode performance due to high memory overhead for large context lengths. To address this, we use a bitmap-based sparse format and a custom attention kernel capable of compressing and directly computing over compressed caches pruned to arbitrary sparsity patterns, significantly accelerating memory-bound operations in decode computations and thereby compensating for the overhead of runtime pruning and compression. Our custom attention kernel coupled with the bitmap-based format delivers substantial compression of KV cache upto 45% of dense inference and thereby enables longer context length and increased tokens/sec throughput of upto 2.23x compared to dense inference. Our pruning mechanism and sparse attention kernel is available at https://github.com/dhjoo98/mustafar.
Endor: Hardware-Friendly Sparse Format for Offloaded LLM Inference
Jun 17, 2024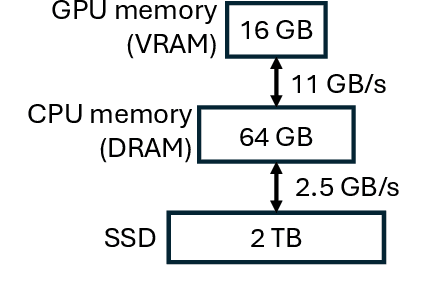
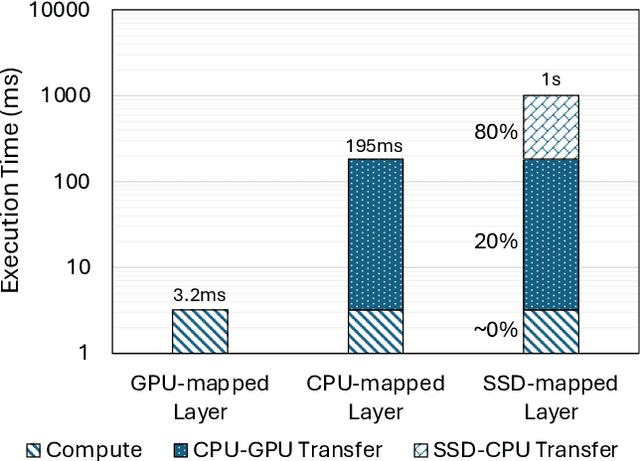
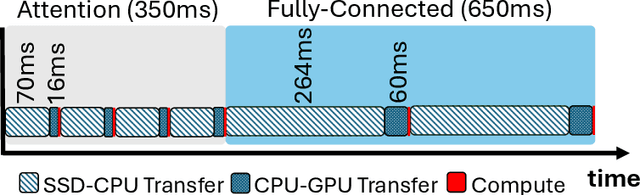

The increasing size of large language models (LLMs) challenges their usage on resource-constrained platforms. For example, memory on modern GPUs is insufficient to hold LLMs that are hundreds of Gigabytes in size. Offloading is a popular method to escape this constraint by storing weights of an LLM model to host CPU memory and SSD, then loading each weight to GPU before every use. In our case study of offloaded inference, we found that due to the low bandwidth between storage devices and GPU, the latency of transferring large model weights from its offloaded location to GPU memory becomes the critical bottleneck with actual compute taking nearly 0% of runtime. To effectively reduce the weight transfer latency, we propose a novel sparse format that compresses the unstructured sparse pattern of pruned LLM weights to non-zero values with high compression ratio and low decompression overhead. Endor achieves this by expressing the positions of non-zero elements with a bitmap. Compared to offloaded inference using the popular Huggingface Accelerate, applying Endor accelerates OPT-66B by 1.70x and Llama2-70B by 1.78x. When direct weight transfer from SSD to GPU is leveraged, Endor achieves 2.25x speedup on OPT-66B and 2.37x speedup on Llama2-70B.
Misam: Using ML in Dataflow Selection of Sparse-Sparse Matrix Multiplication
Jun 14, 2024Sparse matrix-matrix multiplication (SpGEMM) is a critical operation in numerous fields, including scientific computing, graph analytics, and deep learning. These applications exploit the sparsity of matrices to reduce storage and computational demands. However, the irregular structure of sparse matrices poses significant challenges for performance optimization. Traditional hardware accelerators are tailored for specific sparsity patterns with fixed dataflow schemes - inner, outer, and row-wise but often perform suboptimally when the actual sparsity deviates from these predetermined patterns. As the use of SpGEMM expands across various domains, each with distinct sparsity characteristics, the demand for hardware accelerators that can efficiently handle a range of sparsity patterns is increasing. This paper presents a machine learning based approach for adaptively selecting the most appropriate dataflow scheme for SpGEMM tasks with diverse sparsity patterns. By employing decision trees and deep reinforcement learning, we explore the potential of these techniques to surpass heuristic-based methods in identifying optimal dataflow schemes. We evaluate our models by comparing their performance with that of a heuristic, highlighting the strengths and weaknesses of each approach. Our findings suggest that using machine learning for dynamic dataflow selection in hardware accelerators can provide upto 28 times gains.
Context-Aware Task Handling in Resource-Constrained Robots with Virtualization
Apr 09, 2021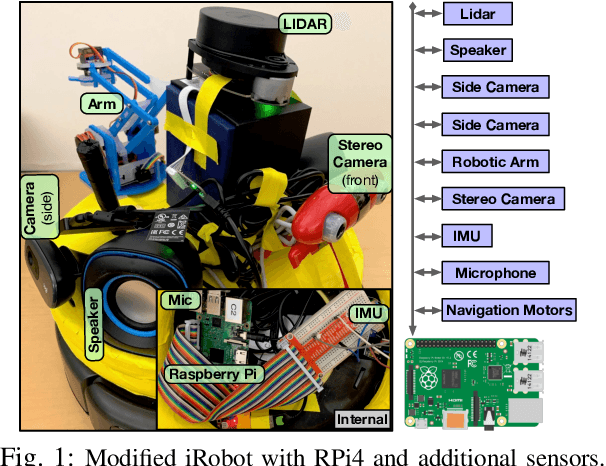
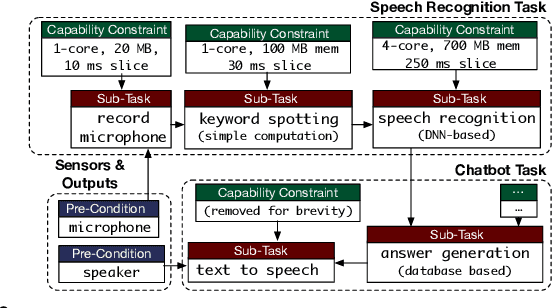

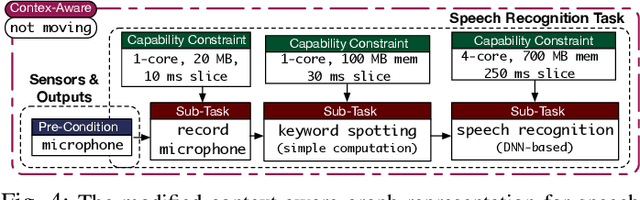
Intelligent mobile robots are critical in several scenarios. However, as their computational resources are limited, mobile robots struggle to handle several tasks concurrently and yet guaranteeing real-timeliness. To address this challenge and improve the real-timeliness of critical tasks under resource constraints, we propose a fast context-aware task handling technique. To effectively handling tasks in real-time, our proposed context-aware technique comprises of three main ingredients: (i) a dynamic time-sharing mechanism, coupled with (ii) an event-driven task scheduling using reactive programming paradigm to mindfully use the limited resources; and, (iii) a lightweight virtualized execution to easily integrate functionalities and their dependencies. We showcase our technique on a Raspberry-Pi-based robot with a variety of tasks such as Simultaneous localization and mapping (SLAM), sign detection, and speech recognition with a 42% speedup in total execution time compared to the common Linux scheduler.
Edge-Tailored Perception: Fast Inferencing in-the-Edge with Efficient Model Distribution
Mar 13, 2020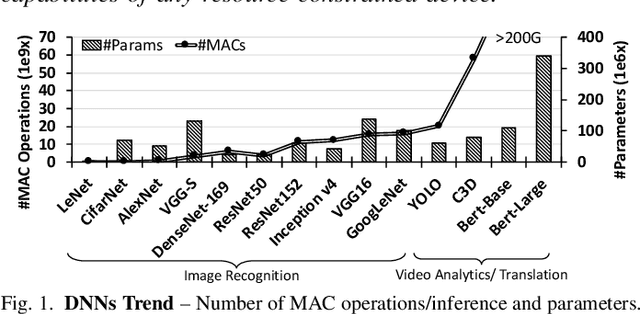
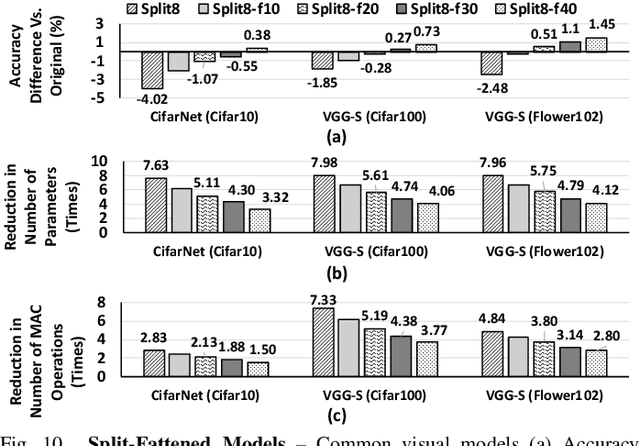
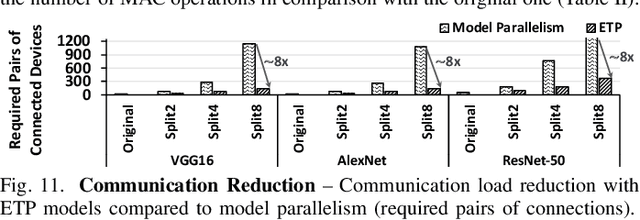
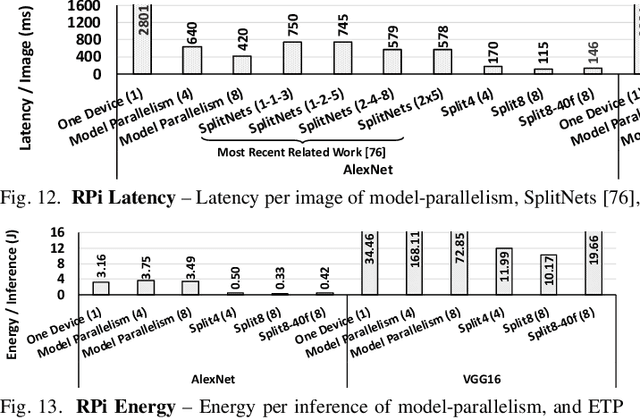
The rise of deep neural networks (DNNs) is inspiring new studies in myriad of edge use cases with robots, autonomous agents, and Internet-of-things (IoT) devices. However, in-the-edge inferencing of DNNs is still a severe challenge mainly because of the contradiction between the inherent intensive resource requirements and the tight resource availability in several edge domains. Further, as communication is costly, taking advantage of other available edge devices is not an effective solution in edge domains. Therefore, to benefit from available compute resources with low communication overhead, we propose new edge-tailored perception (ETP) models that consist of several almost-independent and narrow branches. ETP models offer close-to-minimum communication overheads with better distribution opportunities while significantly reducing memory and computation footprints, all with a trivial accuracy loss for not accuracy-critical tasks. To show the benefits, we deploy ETP models on two real systems, Raspberry Pis and edge-level PYNQ FPGAs. Additionally, we share our insights about tailoring a systolic-based architecture for edge computing with FPGA implementations. ETP models created based on LeNet, CifarNet, VGG-S/16, AlexNet, and ResNets and trained on MNIST, CIFAR10/100, Flower102, and ImageNet, achieve a maximum and average speedups of 56x and 7x, compared to originals. ETP is an addition to existing single-device optimizations for embedded devices by enabling the exploitation of multiple devices. As an example, we show applying pruning and quantization on ETP models improves the average speedup to 33x.