 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Tailored Perception: Fast Inferencing in-the-Edge with Efficient Model Distribution
Paper and Code
Mar 13, 2020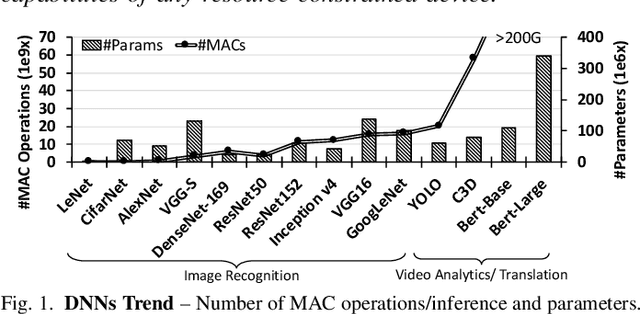
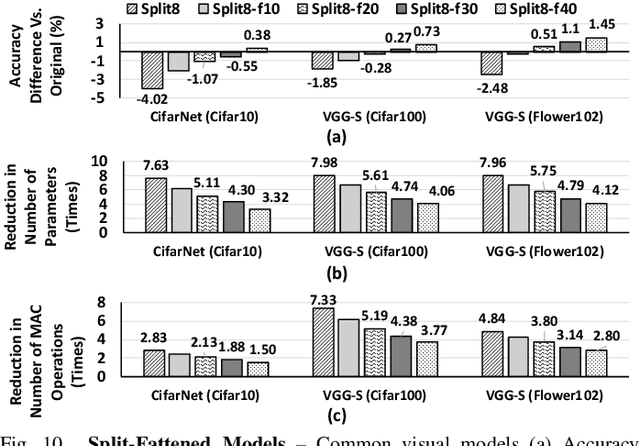
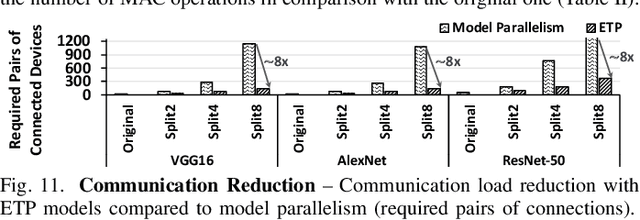
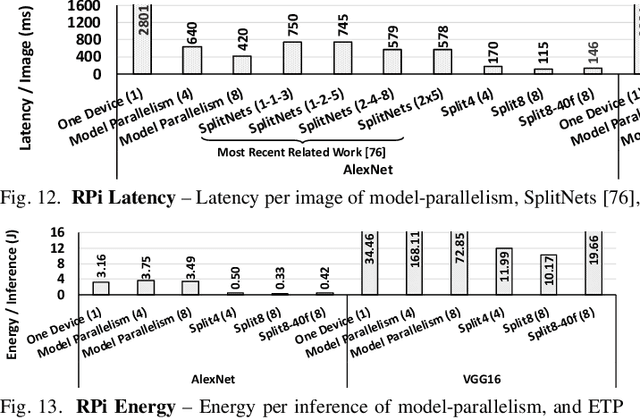
The rise of deep neural networks (DNNs) is inspiring new studies in myriad of edge use cases with robots, autonomous agents, and Internet-of-things (IoT) devices. However, in-the-edge inferencing of DNNs is still a severe challenge mainly because of the contradiction between the inherent intensive resource requirements and the tight resource availability in several edge domains. Further, as communication is costly, taking advantage of other available edge devices is not an effective solution in edge domains. Therefore, to benefit from available compute resources with low communication overhead, we propose new edge-tailored perception (ETP) models that consist of several almost-independent and narrow branches. ETP models offer close-to-minimum communication overheads with better distribution opportunities while significantly reducing memory and computation footprints, all with a trivial accuracy loss for not accuracy-critical tasks. To show the benefits, we deploy ETP models on two real systems, Raspberry Pis and edge-level PYNQ FPGAs. Additionally, we share our insights about tailoring a systolic-based architecture for edge computing with FPGA implementations. ETP models created based on LeNet, CifarNet, VGG-S/16, AlexNet, and ResNets and trained on MNIST, CIFAR10/100, Flower102, and ImageNet, achieve a maximum and average speedups of 56x and 7x, compared to originals. ETP is an addition to existing single-device optimizations for embedded devices by enabling the exploitation of multiple devices. As an example, we show applying pruning and quantization on ETP models improves the average speedup to 33x.