 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaQuant: Compressing Deep Learning Training Checkpoints via Dynamic Quantization
Paper and Code
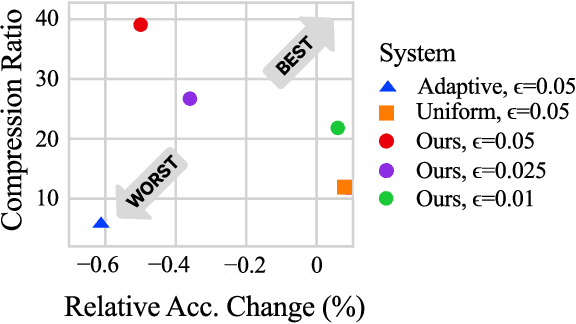

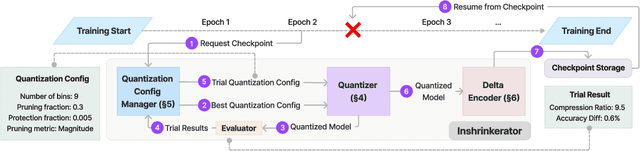
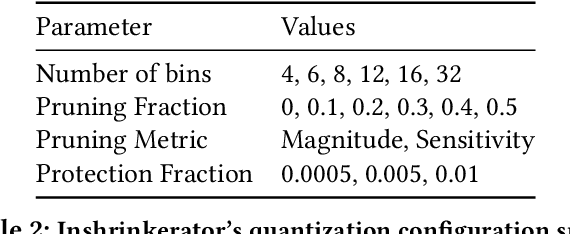
With the increase in the scale of Deep Learning (DL) training workloads in terms of compute resources and time consumption, the likelihood of encountering in-training failures rises substantially, leading to lost work and resource wastage. Such failures are typically offset by a checkpointing mechanism, which comes at the cost of storage and network bandwidth overhead. State-of-the-art approaches involve lossy model compression mechanisms, which induce a tradeoff between the resulting model quality (accuracy) and compression ratio. Delta compression is then also used to further reduce the overhead by only storing the difference between consecutive checkpoints. We make a key enabling observation that the sensitivity of model weights to compression varies during training, and different weights benefit from different quantization levels (ranging from retaining full precision to pruning). We propose (1) a non-uniform quantization scheme that leverages this variation, (2) an efficient search mechanism to dynamically adjust to the best quantization configurations, and (3) a quantization-aware delta compression mechanism that rearranges weights to minimize checkpoint differences, thereby maximizing compression. We instantiate these contributions in DynaQuant - a framework for DL workload checkpoint compression. Our experiments show that DynaQuant consistently achieves better tradeoff between accuracy and compression ratios compared to prior works, enabling a compression ratio up to 39x and withstanding up to 10 restores with negligible accuracy impact for fault-tolerant training. DynaQuant achieves at least an order of magnitude reduction in checkpoint storage overhead for training failure recovery as well as transfer learning use cases without any loss of accuracy