 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceFormer: Speech-Driven 3D Facial Animation with Transformers
Dec 28, 2021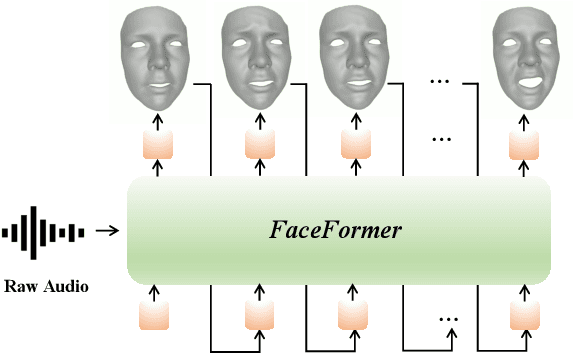
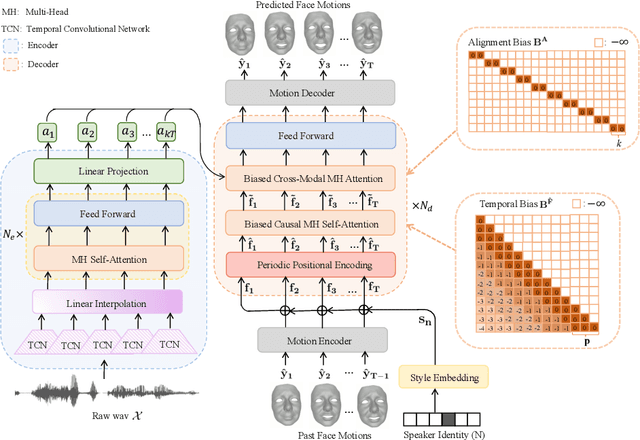

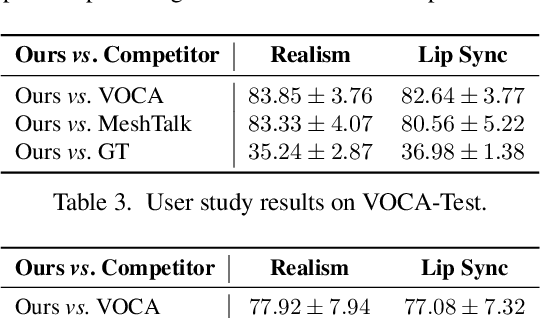
Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts. We encourage watching the video. The code will be made available.
Joint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation
Dec 07, 2021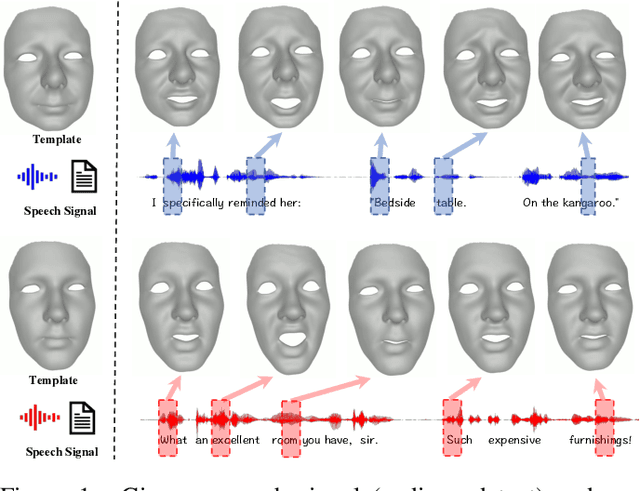
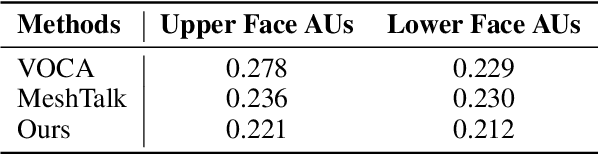
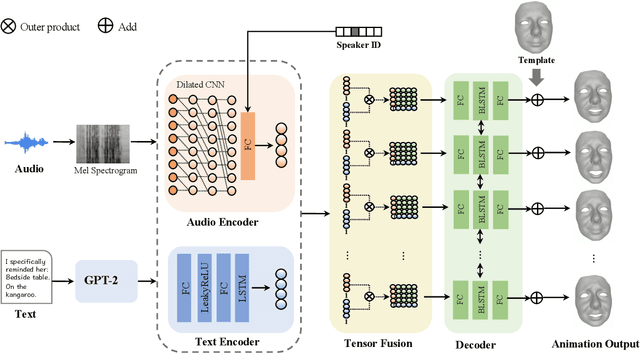
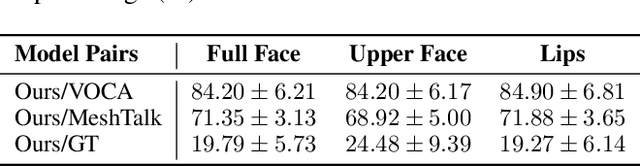
Speech-driven 3D facial animation with accurate lip synchronization has been widely studied. However, synthesizing realistic motions for the entire face during speech has rarely been explored. In this work, we present a joint audio-text model to capture the contextual information for expressive speech-driven 3D facial animation. The existing datasets are collected to cover as many different phonemes as possible instead of sentences, thus limiting the capability of the audio-based model to learn more diverse contexts. To address this, we propose to leverage the contextual text embeddings extracted from the powerful pre-trained language model that has learned rich contextual representations from large-scale text data. Our hypothesis is that the text features can disambiguate the variations in upper face expressions, which are not strongly correlated with the audio. In contrast to prior approaches which learn phoneme-level features from the text, we investigate the high-level contextual text features for speech-driven 3D facial animation. We show that the combined acoustic and textual modalities can synthesize realistic facial expressions while maintaining audio-lip synchronization. We conduct the quantitative and qualitative evaluations as well as the perceptual user study. The results demonstrate the superior performance of our model against existing state-of-the-art approaches.
Facial Action Unit Intensity Estimation via Semantic Correspondence Learning with Dynamic Graph Convolution
Apr 20, 2020
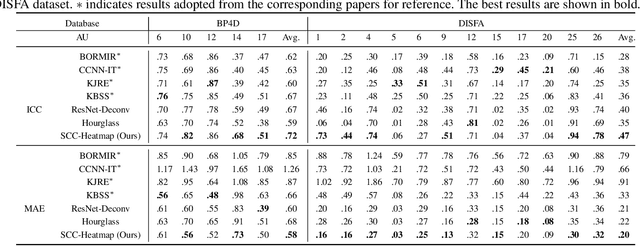
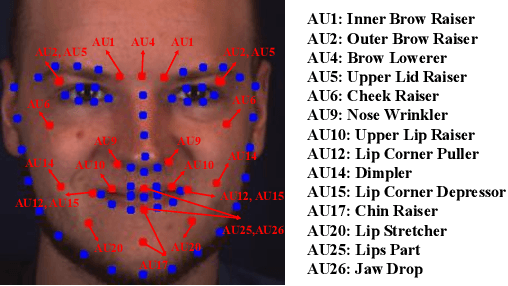
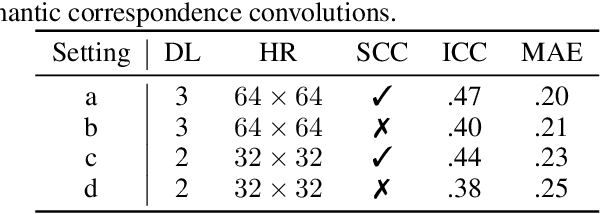
The intensity estimation of facial action units (AUs) is challenging due to subtle changes in the person's facial appearance. Previous approaches mainly rely on probabilistic models or predefined rules for modeling co-occurrence relationships among AUs, leading to limited generalization. In contrast, we present a new learning framework that automatically learns the latent relationships of AUs via establishing semantic correspondences between feature maps. In the heatmap regression-based network, feature maps preserve rich semantic information associated with AU intensities and locations. Moreover, the AU co-occurring pattern can be reflected by activating a set of feature channels, where each channel encodes a specific visual pattern of AU. This motivates us to model the correlation among feature channels, which implicitly represents the co-occurrence relationship of AU intensity levels. Specifically, we introduce a semantic correspondence convolution (SCC) module to dynamically compute the correspondences from deep and low resolution feature maps, and thus enhancing the discriminability of features. The experimental results demonstrate the effectiveness and the superior performance of our method on two benchmark datasets.
Multi-Region Ensemble Convolutional Neural Network for Facial Expression Recognition
Jul 12, 2018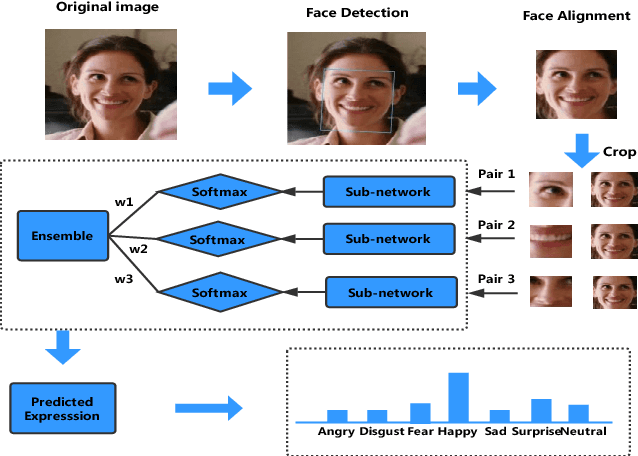
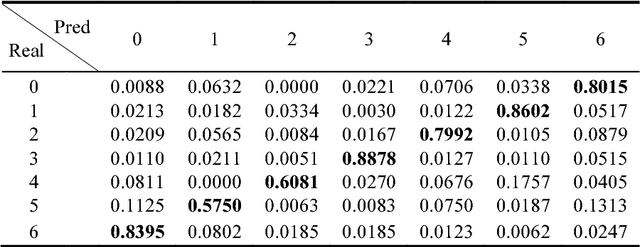

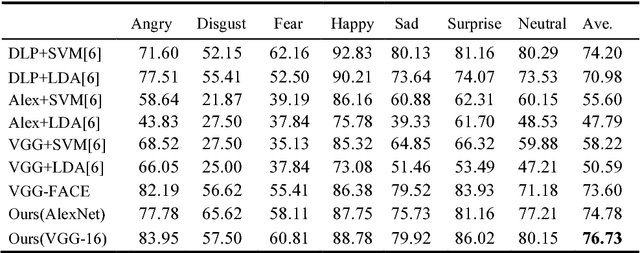
Facial expressions play an important role in conveying the emotional states of human beings. Recently, deep learning approaches have been applied to image recognition field due to the discriminative power of Convolutional Neural Network (CNN). In this paper, we first propose a novel Multi-Region Ensemble CNN (MRE-CNN) framework for facial expression recognition, which aims to enhance the learning power of CNN models by capturing both the global and the local features from multiple human face sub-regions. Second, the weighted prediction scores from each sub-network are aggregated to produce the final prediction of high accuracy. Third, we investigate the effects of different sub-regions of the whole face on facial expression recognition. Our proposed method is evaluated based on two well-known publicly available facial expression databases: AFEW 7.0 and RAF-DB, and has been shown to achieve the state-of-the-art recognition accuracy.