 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMDAgent: An Autonomous Framework for Post-Training Pipeline Optimization via LLM Agents
May 28, 2025Large Language Models (LLMs) have demonstrated exceptional performance across a wide range of tasks. To further tailor LLMs to specific domains or applications, post-training techniques such as Supervised Fine-Tuning (SFT), Preference Learning, and model merging are commonly employed. While each of these methods has been extensively studied in isolation, the automated construction of complete post-training pipelines remains an underexplored area. Existing approaches typically rely on manual design or focus narrowly on optimizing individual components, such as data ordering or merging strategies. In this work, we introduce LaMDAgent (short for Language Model Developing Agent), a novel framework that autonomously constructs and optimizes full post-training pipelines through the use of LLM-based agents. LaMDAgent systematically explores diverse model generation techniques, datasets, and hyperparameter configurations, leveraging task-based feedback to discover high-performing pipelines with minimal human intervention. Our experiments show that LaMDAgent improves tool-use accuracy by 9.0 points while preserving instruction-following capabilities. Moreover, it uncovers effective post-training strategies that are often overlooked by conventional human-driven exploration. We further analyze the impact of data and model size scaling to reduce computational costs on the exploration, finding that model size scalings introduces new challenges, whereas scaling data size enables cost-effective pipeline discovery.
Mining Hidden Thoughts from Texts: Evaluating Continual Pretraining with Synthetic Data for LLM Reasoning
May 15, 2025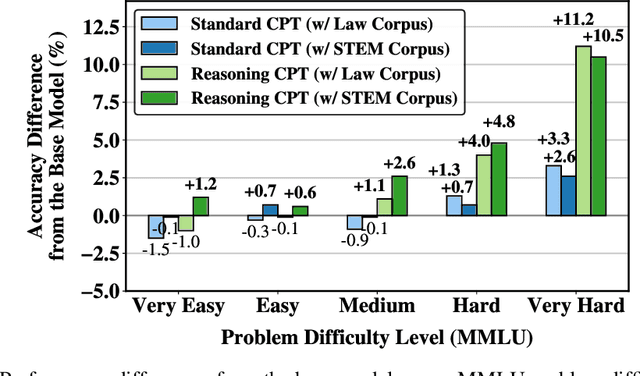

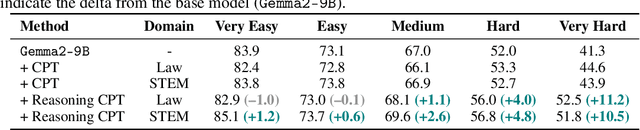

Large Language Models (LLMs) have demonstrated significant improvements in reasoning capabilities through supervised fine-tuning and reinforcement learning. However, when training reasoning models, these approaches are primarily applicable to specific domains such as mathematics and programming, which imposes fundamental constraints on the breadth and scalability of training data. In contrast, continual pretraining (CPT) offers the advantage of not requiring task-specific signals. Nevertheless, how to effectively synthesize training data for reasoning and how such data affect a wide range of domains remain largely unexplored. This study provides a detailed evaluation of Reasoning CPT, a form of CPT that uses synthetic data to reconstruct the hidden thought processes underlying texts, based on the premise that texts are the result of the author's thinking process. Specifically, we apply Reasoning CPT to Gemma2-9B using synthetic data with hidden thoughts derived from STEM and Law corpora, and compare it to standard CPT on the MMLU benchmark. Our analysis reveals that Reasoning CPT consistently improves performance across all evaluated domains. Notably, reasoning skills acquired in one domain transfer effectively to others; the performance gap with conventional methods widens as problem difficulty increases, with gains of up to 8 points on the most challenging problems. Furthermore, models trained with hidden thoughts learn to adjust the depth of their reasoning according to problem difficulty.
DeLTa: A Decoding Strategy based on Logit Trajectory Prediction Improves Factuality and Reasoning Ability
Mar 04, 2025



Large Language Models (LLMs) are increasingly being used in real-world applications. However, concerns about the reliability of the content they generate persist, as it frequently deviates from factual correctness or exhibits deficiencies in logical reasoning. This paper proposes a novel decoding strategy aimed at enhancing both factual accuracy and inferential reasoning without requiring any modifications to the architecture or pre-trained parameters of LLMs. Our approach adjusts next-token probabilities by analyzing the trajectory of logits from lower to higher layers in Transformers and applying linear regression. We find that this Decoding by Logit Trajectory-based approach (DeLTa) effectively reinforces factuality and reasoning while mitigating incorrect generation. Experiments on TruthfulQA demonstrate that DeLTa attains up to a 4.9% improvement over the baseline. Furthermore, it enhances performance by up to 8.1% on StrategyQA and 7.3% on GSM8K, both of which demand strong reasoning capabilities.
Can Large Language Models Invent Algorithms to Improve Themselves?
Oct 21, 2024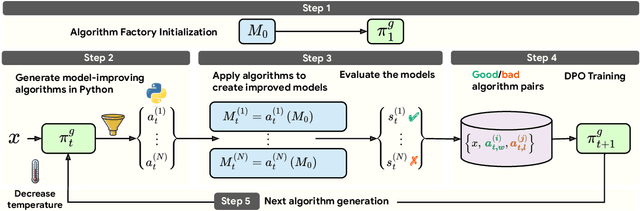
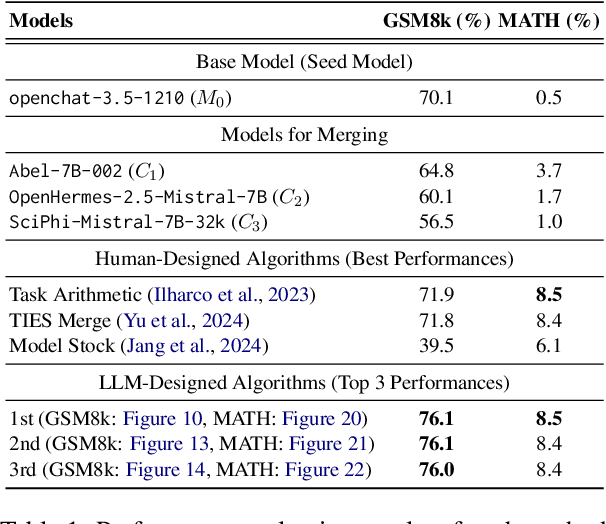
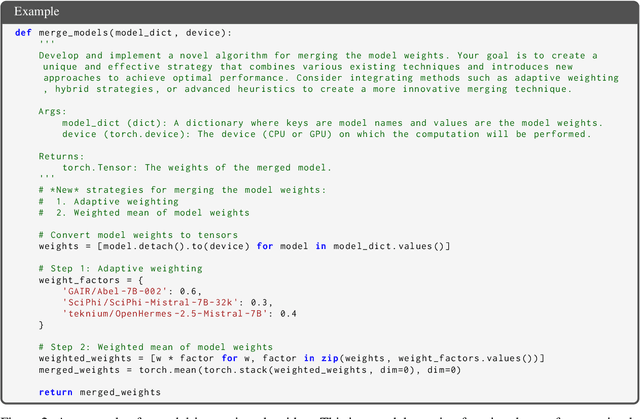
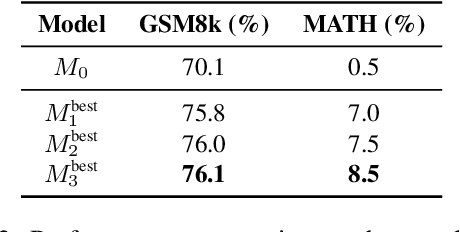
Large Language Models (LLMs) have shown remarkable performance improvements and are rapidly gaining adoption in industry. However, the methods for improving LLMs are still designed by humans, which restricts the invention of new model-improving algorithms to human expertise and imagination. To address this, we propose the Self-Developing framework, which enables LLMs to autonomously generate and learn model-improvement algorithms. In this framework, the seed model generates, applies, and evaluates model-improving algorithms, continuously improving both the seed model and the algorithms themselves. In mathematical reasoning tasks, Self-Developing not only creates models that surpass the seed model but also consistently outperforms models created using human-designed algorithms. Additionally, these LLM-discovered algorithms demonstrate strong effectiveness, including transferability to out-of-domain models.
Self-Organized Agents: A LLM Multi-Agent Framework toward Ultra Large-Scale Code Generation and Optimization
Apr 02, 2024



Recent advancements in automatic code generation using large language model (LLM) agent have brought us closer to the future of automated software development. However, existing single-agent approaches face limitations in generating and improving large-scale, complex codebases due to constraints in context length. To tackle this challenge, we propose Self-Organized multi-Agent framework (SoA), a novel multi-agent framework that enables the scalable and efficient generation and optimization of large-scale code. In SoA, self-organized agents operate independently to generate and modify code components while seamlessly collaborating to construct the overall codebase. A key feature of our framework is the automatic multiplication of agents based on problem complexity, allowing for dynamic scalability. This enables the overall code volume to be increased indefinitely according to the number of agents, while the amount of code managed by each agent remains constant. We evaluate SoA on the HumanEval benchmark and demonstrate that, compared to a single-agent system, each agent in SoA handles significantly less code, yet the overall generated code is substantially greater. Moreover, SoA surpasses the powerful single-agent baseline by 5% in terms of Pass@1 accuracy.
Knowledge Sanitization of Large Language Models
Sep 21, 2023
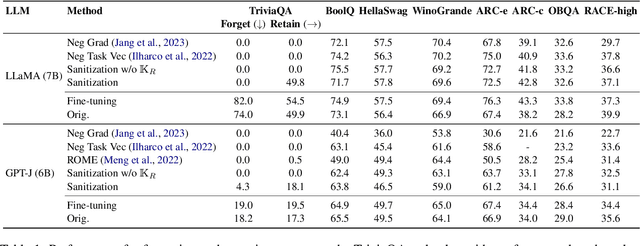
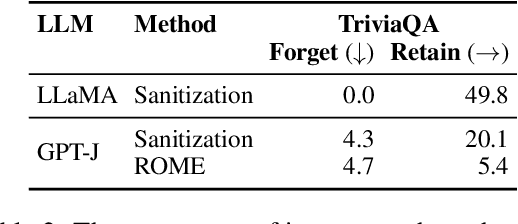

We explore a knowledge sanitization approach to mitigate the privacy concerns associated with large language models (LLMs). LLMs trained on a large corpus of Web data can memorize and potentially reveal sensitive or confidential information, raising critical security concerns. Our technique fine-tunes these models, prompting them to generate harmless responses such as ``I don't know'' when queried about specific information. Experimental results in a closed-book question-answering task show that our straightforward method not only minimizes particular knowledge leakage but also preserves the overall performance of LLM. These two advantages strengthen the defense against extraction attacks and reduces the emission of harmful content such as hallucinations.
Evaluating the Robustness of Discrete Prompts
Feb 11, 2023
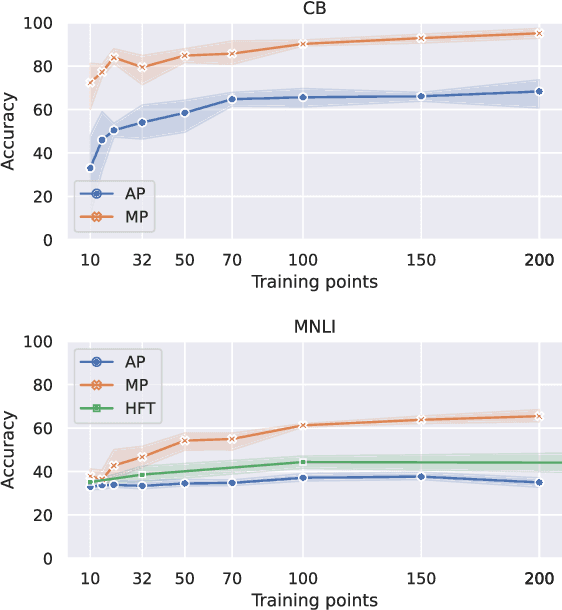

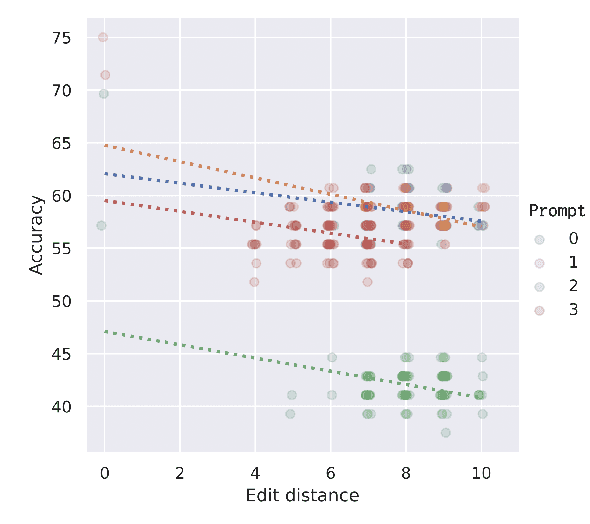
Discrete prompts have been used for fine-tuning Pre-trained Language Models for diverse NLP tasks. In particular, automatic methods that generate discrete prompts from a small set of training instances have reported superior performance. However, a closer look at the learnt prompts reveals that they contain noisy and counter-intuitive lexical constructs that would not be encountered in manually-written prompts. This raises an important yet understudied question regarding the robustness of automatically learnt discrete prompts when used in downstream tasks. To address this question, we conduct a systematic study of the robustness of discrete prompts by applying carefully designed perturbations into an application using AutoPrompt and then measure their performance in two Natural Language Inference (NLI) datasets. Our experimental results show that although the discrete prompt-based method remains relatively robust against perturbations to NLI inputs, they are highly sensitive to other types of perturbations such as shuffling and deletion of prompt tokens. Moreover, they generalize poorly across different NLI datasets. We hope our findings will inspire future work on robust discrete prompt learning.
Subspace-based Set Operations on a Pre-trained Word Embedding Space
Oct 24, 2022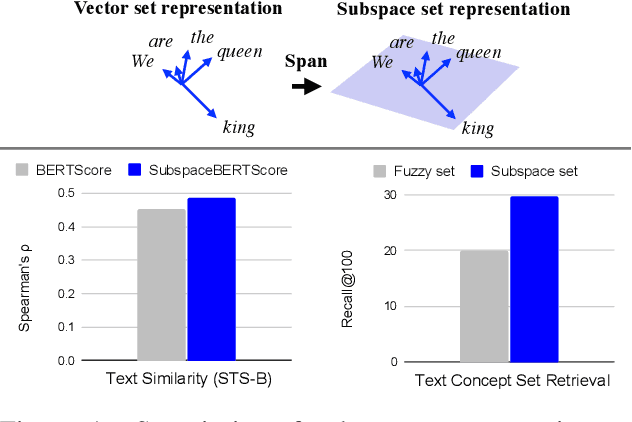
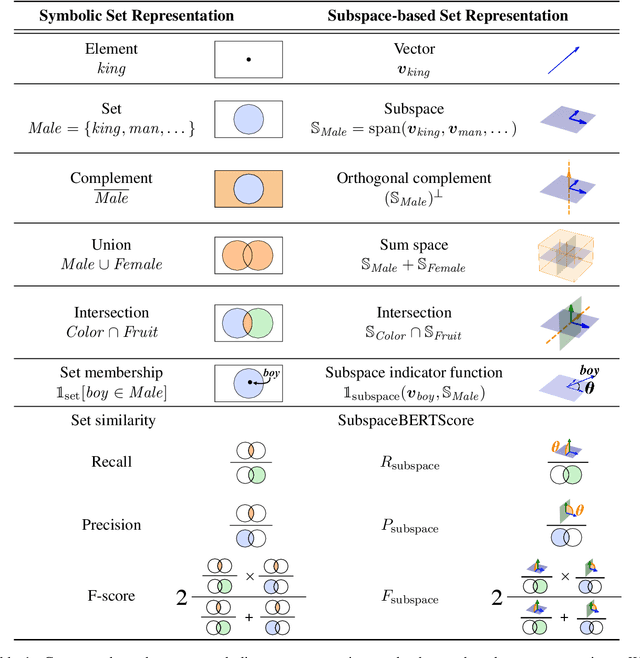
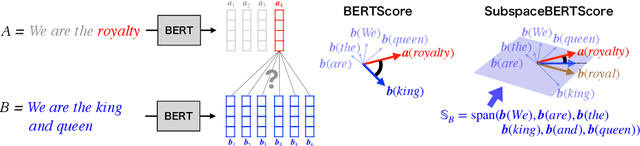
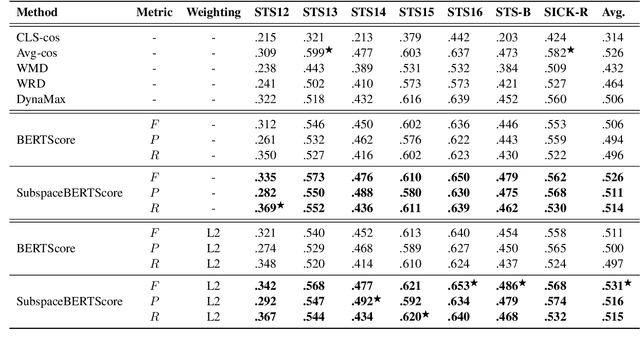
Word embedding is a fundamental technology in natural language processing. It is often exploited for tasks using sets of words, although standard methods for representing word sets and set operations remain limited. If we can leverage the advantage of word embedding for such set operations, we can calculate sentence similarity and find words that effectively share a concept with a given word set in a straightforward way. In this study, we formulate representations of sets and set operations in a pre-trained word embedding space. Inspired by \textit{quantum logic}, we propose a novel formulation of set operations using subspaces in a pre-trained word embedding space. Based on our definitions, we propose two metrics based on the degree to which a word belongs to a set and the similarity between embedding two sets. Our experiments with Text Concept Set Retrieval and Semantic Textual Similarity tasks demonstrated the effectiveness of our proposed method.
Reflection-based Word Attribute Transfer
Jul 07, 2020Word embeddings, which often represent such analogic relations as king - man + woman = queen, can be used to change a word's attribute, including its gender. For transferring king into queen in this analogy-based manner, we subtract a difference vector man - woman based on the knowledge that king is male. However, developing such knowledge is very costly for words and attributes. In this work, we propose a novel method for word attribute transfer based on reflection mappings without such an analogy operation. Experimental results show that our proposed method can transfer the word attributes of the given words without changing the words that do not have the target attributes.