 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation
Jul 17, 2025



Large language models (LLMs) can perform recommendation tasks by taking prompts written in natural language as input. Compared to traditional methods such as collaborative filtering, LLM-based recommendation offers advantages in handling cold-start, cross-domain, and zero-shot scenarios, as well as supporting flexible input formats and generating explanations of user behavior. In this paper, we focus on a single-user setting, where no information from other users is used. This setting is practical for privacy-sensitive or data-limited applications. In such cases, prompt engineering becomes especially important for controlling the output generated by the LLM. We conduct a large-scale comparison of 23 prompt types across 8 public datasets and 12 LLMs. We use statistical tests and linear mixed-effects models to evaluate both accuracy and inference cost. Our results show that for cost-efficient LLMs, three types of prompts are especially effective: those that rephrase instructions, consider background knowledge, and make the reasoning process easier to follow. For high-performance LLMs, simple prompts often outperform more complex ones while reducing cost. In contrast, commonly used prompting styles in natural language processing, such as step-by-step reasoning, or the use of reasoning models often lead to lower accuracy. Based on these findings, we provide practical suggestions for selecting prompts and LLMs depending on the required balance between accuracy and cost.
Are Longer Prompts Always Better? Prompt Selection in Large Language Models for Recommendation Systems
Dec 19, 2024

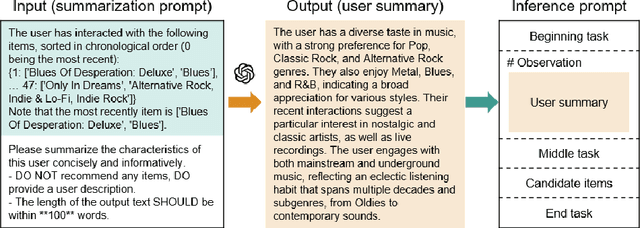

In large language models (LLM)-based recommendation systems (LLM-RSs), accurately predicting user preferences by leveraging the general knowledge of LLMs is possible without requiring extensive training data. By converting recommendation tasks into natural language inputs called prompts, LLM-RSs can efficiently solve issues that have been difficult to address due to data scarcity but are crucial in applications such as cold-start and cross-domain problems. However, when applying this in practice, selecting the prompt that matches tasks and data is essential. Although numerous prompts have been proposed in LLM-RSs and representing the target user in prompts significantly impacts recommendation accuracy, there are still no clear guidelines for selecting specific prompts. In this paper, we categorize and analyze prompts from previous research to establish practical prompt selection guidelines. Through 450 experiments with 90 prompts and five real-world datasets, we examined the relationship between prompts and dataset characteristics in recommendation accuracy. We found that no single prompt consistently outperforms others; thus, selecting prompts on the basis of dataset characteristics is crucial. Here, we propose a prompt selection method that achieves higher accuracy with minimal validation data. Because increasing the number of prompts to explore raises costs, we also introduce a cost-efficient strategy using high-performance and cost-efficient LLMs, significantly reducing exploration costs while maintaining high prediction accuracy. Our work offers valuable insights into the prompt selection, advancing accurate and efficient LLM-RSs.
Optimizing Low-Resource Language Model Training: Comprehensive Analysis of Multi-Epoch, Multi-Lingual, and Two-Stage Approaches
Oct 16, 2024


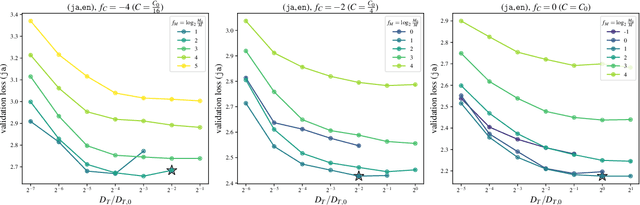
In this paper, we address the challenge of optimizing training setups for Large Language Models (LLMs) of low-resource language with a limited amount of corpus. Existing works adopt multi-epoch, multi-lingual, and two-stage training to utilize the limited target language corpus efficiently. However, there is still a lack of understanding about the optimal hyperparameter setups for combining these three approaches to train LLMs. We exhaustively explore training setups for low-resource language LLM, combining these three approaches, and found the following insights for efficiently reducing the cost of hyperparameter search: (1) As the amount of target language corpus decreases, the optimal training approach shifts from monolingual single-stage training to multi-lingual two-stage training at a compute budget dependent threshold. (2) The optimal model scale remains stable regardless of the amount of target language corpus, allowing the use of the compute-optimal scale of monolingual training. (3) The optimal number of epochs can be extrapolated from smaller-scale experiments to larger scale using our proposed model. Also, we provide evidence that, in single-stage training, the target language validation loss follows a power law with respect to the target language ratio, with an exponent independent of the amount of data, model scale, and language pair.
LightPAL: Lightweight Passage Retrieval for Open Domain Multi-Document Summarization
Jun 18, 2024



Open-Domain Multi-Document Summarization (ODMDS) is crucial for addressing diverse information needs, which aims to generate a summary as answer to user's query, synthesizing relevant content from multiple documents in a large collection. Existing approaches that first find relevant passages and then generate a summary using a language model are inadequate for ODMDS. This is because open-ended queries often require additional context for the retrieved passages to cover the topic comprehensively, making it challenging to retrieve all relevant passages initially. While iterative retrieval methods have been explored for multi-hop question answering (MQA), they are impractical for ODMDS due to high latency from repeated large language model (LLM) inference for reasoning. To address this issue, we propose LightPAL, a lightweight passage retrieval method for ODMDS that constructs a graph representing passage relationships using an LLM during indexing and employs random walk instead of iterative reasoning and retrieval at inference time. Experiments on ODMDS benchmarks show that LightPAL outperforms baseline retrievers in summary quality while being significantly more efficient than an iterative MQA approach.
Context Quality Matters in Training Fusion-in-Decoder for Extractive Open-Domain Question Answering
Mar 21, 2024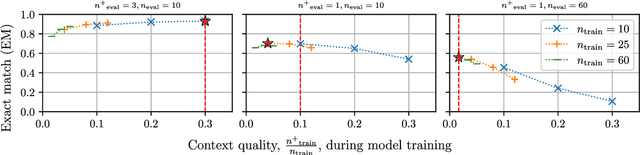

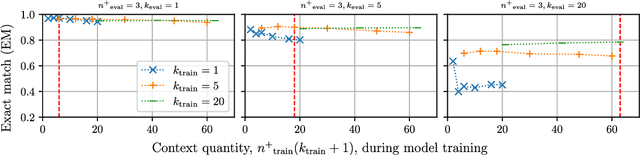

Retrieval-augmented generation models augment knowledge encoded in a language model by providing additional relevant external knowledge (context) during generation. Although it has been shown that the quantity and quality of context impact the performance of retrieval-augmented generation models during inference, limited research explores how these characteristics affect model training. This paper explores how context quantity and quality during model training affect the performance of Fusion-in-Decoder (FiD), the state-of-the-art retrieval-augmented generation model, in extractive open-domain question answering tasks. Experimental results suggest that FiD models overfit to context quality during training and show suboptimal performance when evaluated on different context quality. Through the experimental results, we also reveal FiD models trained with different context quality have different cross-attention distribution patterns. Specifically, as context quality during training increases, FiD models tend to attend more uniformly to each passage in context. Finally, based on these observations, we propose a method to mitigate overfitting to specific context quality by introducing bias to the cross-attention distribution, which we demonstrate to be effective in improving the performance of FiD models on different context quality.
Learning Directly from Grammar Compressed Text
Feb 28, 2020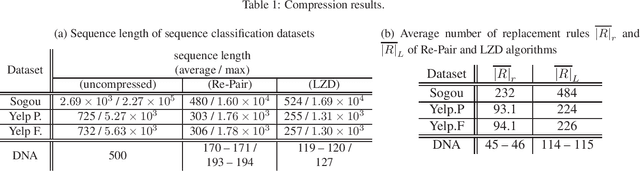
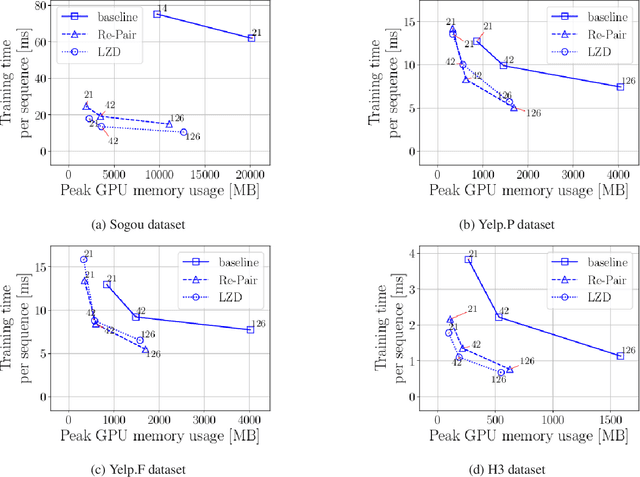

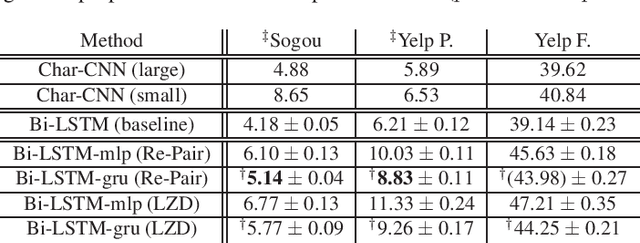
Neural networks using numerous text data have been successfully applied to a variety of tasks. While massive text data is usually compressed using techniques such as grammar compression, almost all of the previous machine learning methods assume already decompressed sequence data as their input. In this paper, we propose a method to directly apply neural sequence models to text data compressed with grammar compression algorithms without decompression. To encode the unique symbols that appear in compression rules, we introduce composer modules to incrementally encode the symbols into vector representations. Through experiments on real datasets, we empirically showed that the proposal model can achieve both memory and computational efficiency while maintaining moderate performance.
Knowledge-Based Distant Regularization in Learning Probabilistic Models
Jun 29, 2018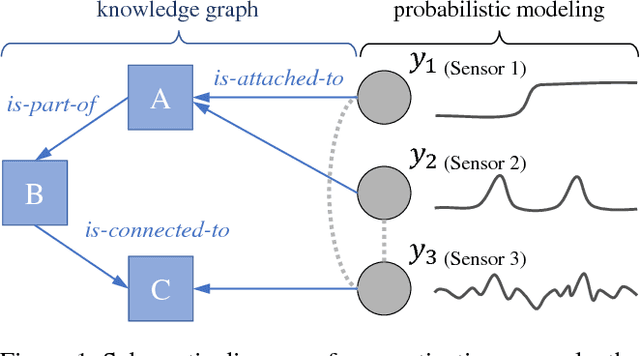

Exploiting the appropriate inductive bias based on the knowledge of data is essential for achieving good performance in statistical machine learning. In practice, however, the domain knowledge of interest often provides information on the relationship of data attributes only distantly, which hinders direct utilization of such domain knowledge in popular regularization methods. In this paper, we propose the knowledge-based distant regularization framework, in which we utilize the distant information encoded in a knowledge graph for regularization of probabilistic model estimation. In particular, we propose to impose prior distributions on model parameters specified by knowledge graph embeddings. As an instance of the proposed framework, we present the factor analysis model with the knowledge-based distant regularization. We show the results of preliminary experiments on the improvement of the generalization capability of such model.