 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Directly from Grammar Compressed Text
Feb 28, 2020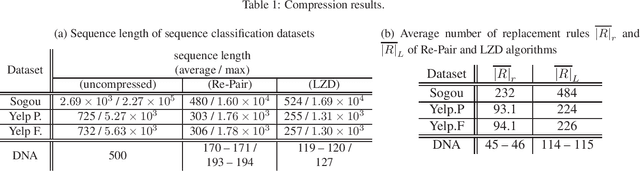
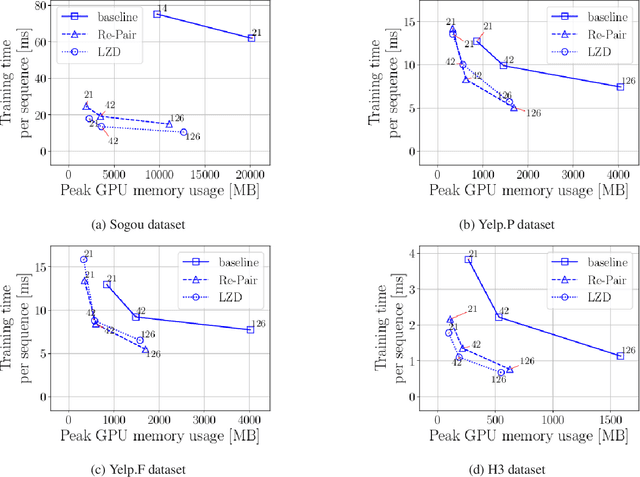

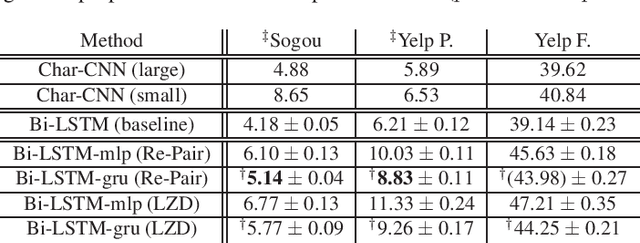
Neural networks using numerous text data have been successfully applied to a variety of tasks. While massive text data is usually compressed using techniques such as grammar compression, almost all of the previous machine learning methods assume already decompressed sequence data as their input. In this paper, we propose a method to directly apply neural sequence models to text data compressed with grammar compression algorithms without decompression. To encode the unique symbols that appear in compression rules, we introduce composer modules to incrementally encode the symbols into vector representations. Through experiments on real datasets, we empirically showed that the proposal model can achieve both memory and computational efficiency while maintaining moderate performance.