 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Really Effective for Training-Free Cold-Start Recommendation?
Dec 15, 2025Recommender systems usually rely on large-scale interaction data to learn from users' past behaviors and make accurate predictions. However, real-world applications often face situations where no training data is available, such as when launching new services or handling entirely new users. In such cases, conventional approaches cannot be applied. This study focuses on training-free recommendation, where no task-specific training is performed, and particularly on \textit{training-free cold-start recommendation} (TFCSR), the more challenging case where the target user has no interactions. Large language models (LLMs) have recently been explored as a promising solution, and numerous studies have been proposed. As the ability of text embedding models (TEMs) increases, they are increasingly recognized as applicable to training-free recommendation, but no prior work has directly compared LLMs and TEMs under identical conditions. We present the first controlled experiments that systematically evaluate these two approaches in the same setting. The results show that TEMs outperform LLM rerankers, and this trend holds not only in cold-start settings but also in warm-start settings with rich interactions. These findings indicate that direct LLM ranking is not the only viable option, contrary to the commonly shared belief, and TEM-based approaches provide a stronger and more scalable basis for training-free recommendation.
Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation
Jul 17, 2025Large language models (LLMs) can perform recommendation tasks by taking prompts written in natural language as input. Compared to traditional methods such as collaborative filtering, LLM-based recommendation offers advantages in handling cold-start, cross-domain, and zero-shot scenarios, as well as supporting flexible input formats and generating explanations of user behavior. In this paper, we focus on a single-user setting, where no information from other users is used. This setting is practical for privacy-sensitive or data-limited applications. In such cases, prompt engineering becomes especially important for controlling the output generated by the LLM. We conduct a large-scale comparison of 23 prompt types across 8 public datasets and 12 LLMs. We use statistical tests and linear mixed-effects models to evaluate both accuracy and inference cost. Our results show that for cost-efficient LLMs, three types of prompts are especially effective: those that rephrase instructions, consider background knowledge, and make the reasoning process easier to follow. For high-performance LLMs, simple prompts often outperform more complex ones while reducing cost. In contrast, commonly used prompting styles in natural language processing, such as step-by-step reasoning, or the use of reasoning models often lead to lower accuracy. Based on these findings, we provide practical suggestions for selecting prompts and LLMs depending on the required balance between accuracy and cost.
Are Longer Prompts Always Better? Prompt Selection in Large Language Models for Recommendation Systems
Dec 19, 2024

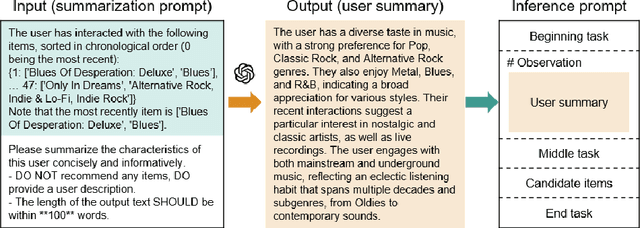

In large language models (LLM)-based recommendation systems (LLM-RSs), accurately predicting user preferences by leveraging the general knowledge of LLMs is possible without requiring extensive training data. By converting recommendation tasks into natural language inputs called prompts, LLM-RSs can efficiently solve issues that have been difficult to address due to data scarcity but are crucial in applications such as cold-start and cross-domain problems. However, when applying this in practice, selecting the prompt that matches tasks and data is essential. Although numerous prompts have been proposed in LLM-RSs and representing the target user in prompts significantly impacts recommendation accuracy, there are still no clear guidelines for selecting specific prompts. In this paper, we categorize and analyze prompts from previous research to establish practical prompt selection guidelines. Through 450 experiments with 90 prompts and five real-world datasets, we examined the relationship between prompts and dataset characteristics in recommendation accuracy. We found that no single prompt consistently outperforms others; thus, selecting prompts on the basis of dataset characteristics is crucial. Here, we propose a prompt selection method that achieves higher accuracy with minimal validation data. Because increasing the number of prompts to explore raises costs, we also introduce a cost-efficient strategy using high-performance and cost-efficient LLMs, significantly reducing exploration costs while maintaining high prediction accuracy. Our work offers valuable insights into the prompt selection, advancing accurate and efficient LLM-RSs.
Kernel method for persistence diagrams via kernel embedding and weight factor
Jun 12, 2017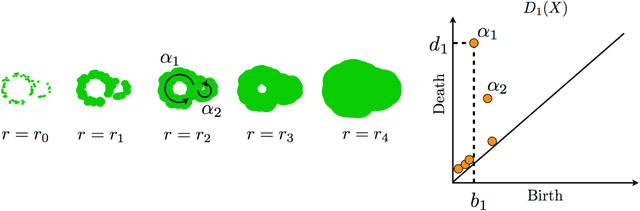
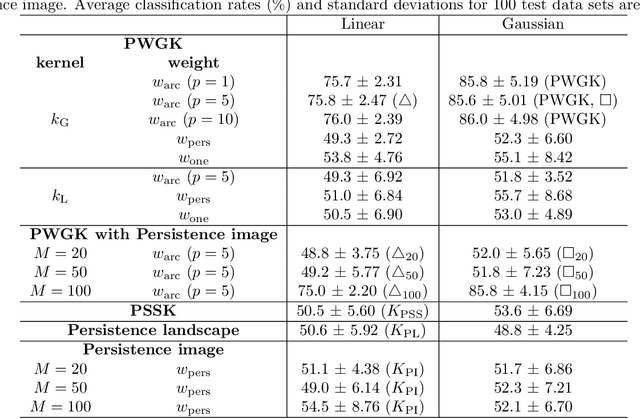

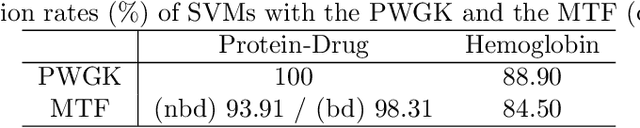
Topological data analysis is an emerging mathematical concept for characterizing shapes in multi-scale data. In this field, persistence diagrams are widely used as a descriptor of the input data, and can distinguish robust and noisy topological properties. Nowadays, it is highly desired to develop a statistical framework on persistence diagrams to deal with practical data. This paper proposes a kernel method on persistence diagrams. A theoretical contribution of our method is that the proposed kernel allows one to control the effect of persistence, and, if necessary, noisy topological properties can be discounted in data analysis. Furthermore, the method provides a fast approximation technique. The method is applied into several problems including practical data in physics, and the results show the advantage compared to the existing kernel method on persistence diagrams.