 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrongly Solving 2048 4x3
Oct 06, 20252048 is a stochastic single-player game involving 16 cells on a 4 by 4 grid, where a player chooses a direction among up, down, left, and right to obtain a score by merging two tiles with the same number located in neighboring cells along the chosen direction. This paper presents that a variant 2048-4x3 12 cells on a 4 by 3 board, one row smaller than the original, has been strongly solved. In this variant, the expected score achieved by an optimal strategy is about $50724.26$ for the most common initial states: ones with two tiles of number 2. The numbers of reachable states and afterstates are identified to be $1,152,817,492,752$ and $739,648,886,170$, respectively. The key technique is to partition state space by the sum of tile numbers on a board, which we call the age of a state. An age is invariant between a state and its successive afterstate after any valid action and is increased two or four by stochastic response from the environment. Therefore, we can partition state space by ages and enumerate all (after)states of an age depending only on states with the recent ages. Similarly, we can identify (after)state values by going along with ages in decreasing order.
The Role of Background Information in Reducing Object Hallucination in Vision-Language Models: Insights from Cutoff API Prompting
Feb 21, 2025Vision-Language Models (VLMs) occasionally generate outputs that contradict input images, constraining their reliability in real-world applications. While visual prompting is reported to suppress hallucinations by augmenting prompts with relevant area inside an image, the effectiveness in terms of the area remains uncertain. This study analyzes success and failure cases of Attention-driven visual prompting in object hallucination, revealing that preserving background context is crucial for mitigating object hallucination.
DEIR: Efficient and Robust Exploration through Discriminative-Model-Based Episodic Intrinsic Rewards
Apr 21, 2023
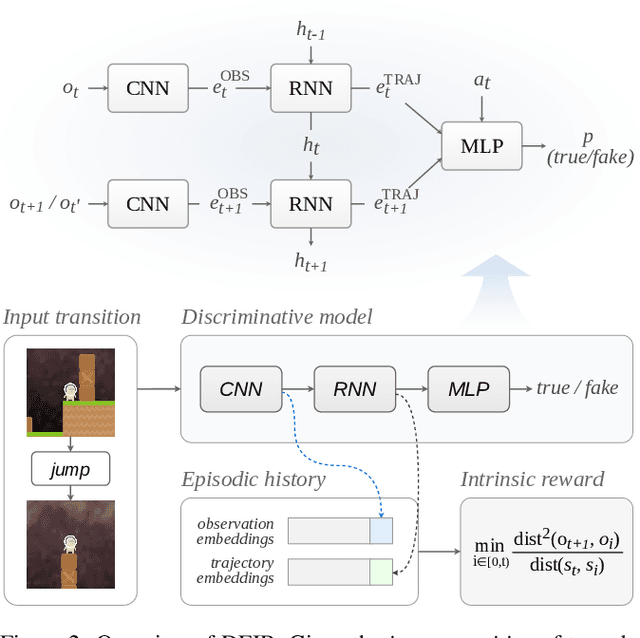


Exploration is a fundamental aspect of reinforcement learning (RL), and its effectiveness crucially decides the performance of RL algorithms, especially when facing sparse extrinsic rewards. Recent studies showed the effectiveness of encouraging exploration with intrinsic rewards estimated from novelty in observations. However, there is a gap between the novelty of an observation and an exploration in general, because the stochasticity in the environment as well as the behavior of an agent may affect the observation. To estimate exploratory behaviors accurately, we propose DEIR, a novel method where we theoretically derive an intrinsic reward from a conditional mutual information term that principally scales with the novelty contributed by agent explorations, and materialize the reward with a discriminative forward model. We conduct extensive experiments in both standard and hardened exploration games in MiniGrid to show that DEIR quickly learns a better policy than baselines. Our evaluations in ProcGen demonstrate both generalization capabilities and the general applicability of our intrinsic reward.
Diverse Exploration via InfoMax Options
Oct 06, 2020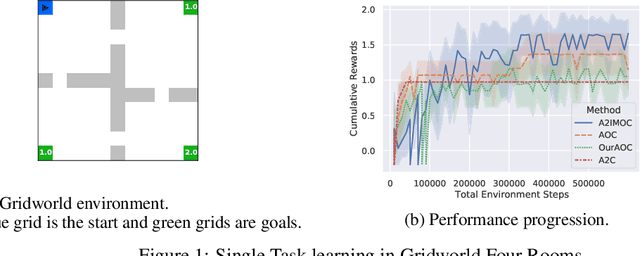
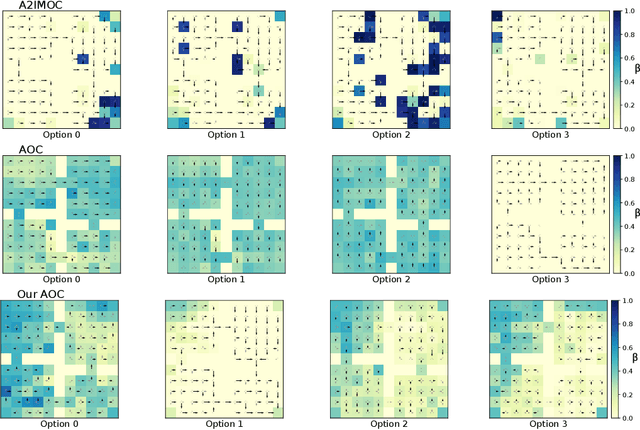
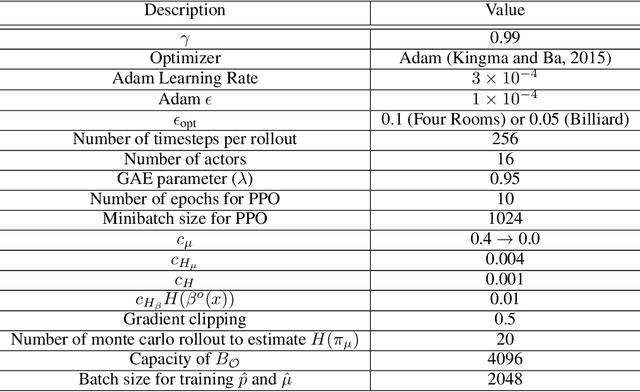
In this paper, we study the problem of autonomously discovering temporally abstracted actions, or options, for exploration in reinforcement learning. For learning diverse options suitable for exploration, we introduce the infomax termination objective defined as the mutual information between options and their corresponding state transitions. We derive a scalable optimization scheme for maximizing this objective via the termination condition of options, yielding the InfoMax Option Critic (IMOC) algorithm. Through illustrative experiments, we empirically show that IMOC learns diverse options and utilizes them for exploration. Moreover, we show that IMOC scales well to continuous control tasks.
Playing Catan with Cross-dimensional Neural Network
Aug 17, 2020


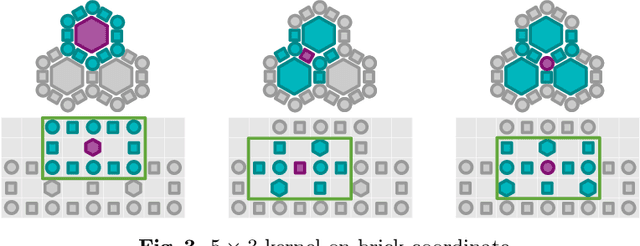
Catan is a strategic board game having interesting properties, including multi-player, imperfect information, stochastic, complex state space structure (hexagonal board where each vertex, edge and face has its own features, cards for each player, etc), and a large action space (including negotiation). Therefore, it is challenging to build AI agents by Reinforcement Learning (RL for short), without domain knowledge nor heuristics. In this paper, we introduce cross-dimensional neural networks to handle a mixture of information sources and a wide variety of outputs, and empirically demonstrate that the network dramatically improves RL in Catan. We also show that, for the first time, a RL agent can outperform jsettler, the best heuristic agent available.
Rogue-Gym: A New Challenge for Generalization in Reinforcement Learning
Apr 17, 2019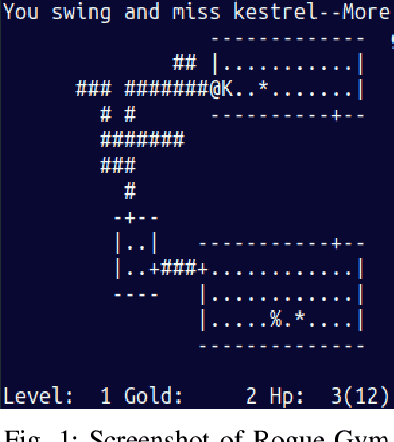
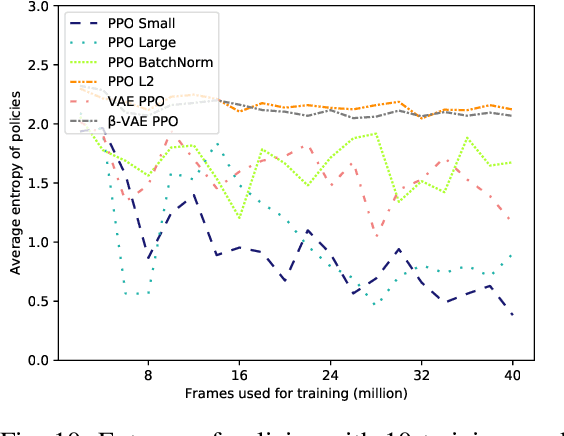
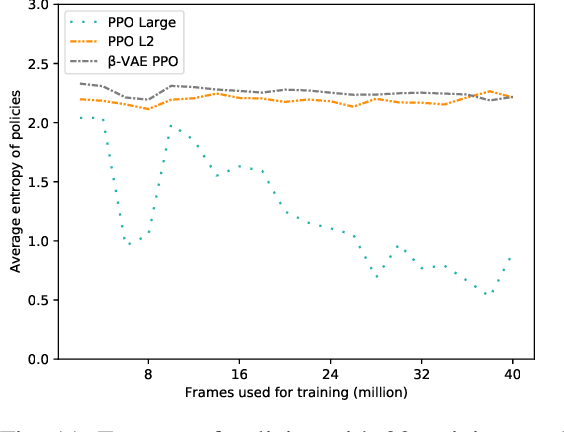
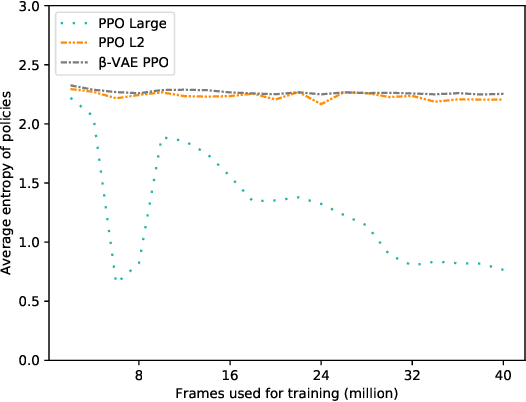
This paper presents Rogue-Gym, that enables agents to learn and play a subset of the original Rogue game with the OpenAI Gym interface. In roguelike games, a player explores a dungeon where each floor is two dimensional grid maze with enemies, golds, and downstairs. Because the map of a dungeon is different each time an agent starts a new game, learning in Rogue-Gym inevitably involves generalization of experiences, in a highly abstract manner. We argue that this generalization in reinforcement learning is a big challenge for AI agents. Recently, deep reinforcement learning (DRL) has succeeded in many games. However, it has been pointed out that agents trained by DRL methods often overfit to the training environment. To investigate this problem, some research environments with procedural content generation have been proposed. Following these studies, we show that our Rogue-Gym imposes a new generalization problem of their policies. In our experiments, we evaluate a standard reinforcement learning method, PPO, with and without enhancements for generalization. The results show that some enhancements work effective, but that there is still a large room for improvement. Therefore, Rogue-Gym a is a new challenging domain for further studies.