 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution of Rewards for Food and Motor Action by Simulating Birth and Death
Jun 21, 2024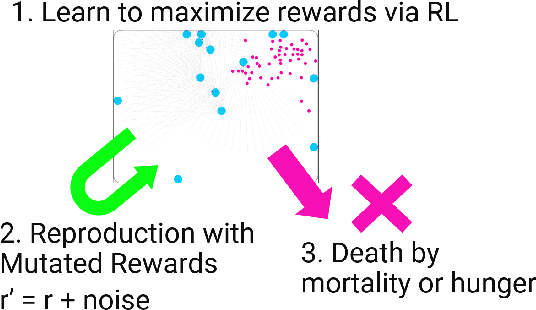

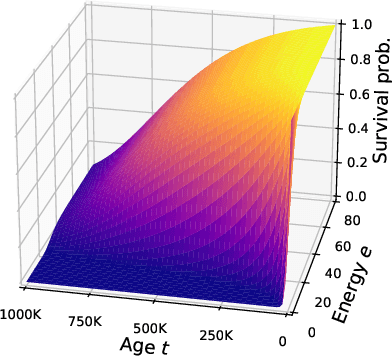
The reward system is one of the fundamental drivers of animal behaviors and is critical for survival and reproduction. Despite its importance, the problem of how the reward system has evolved is underexplored. In this paper, we try to replicate the evolution of biologically plausible reward functions and investigate how environmental conditions affect evolved rewards' shape. For this purpose, we developed a population-based decentralized evolutionary simulation framework, where agents maintain their energy level to live longer and produce more children. Each agent inherits its reward function from its parent subject to mutation and learns to get rewards via reinforcement learning throughout its lifetime. Our results show that biologically reasonable positive rewards for food acquisition and negative rewards for motor action can evolve from randomly initialized ones. However, we also find that the rewards for motor action diverge into two modes: largely positive and slightly negative. The emergence of positive motor action rewards is surprising because it can make agents too active and inefficient in foraging. In environments with poor and poisonous foods, the evolution of rewards for less important foods tends to be unstable, while rewards for normal foods are still stable. These results demonstrate the usefulness of our simulation environment and energy-dependent birth and death model for further studies of the origin of reward systems.
Diverse Exploration via InfoMax Options
Oct 06, 2020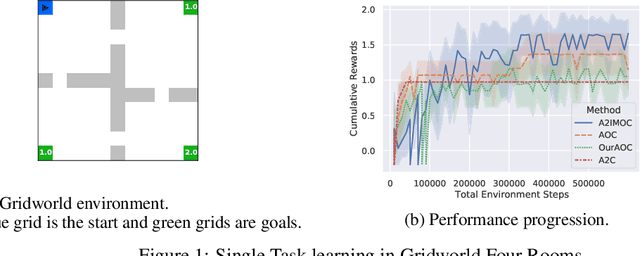
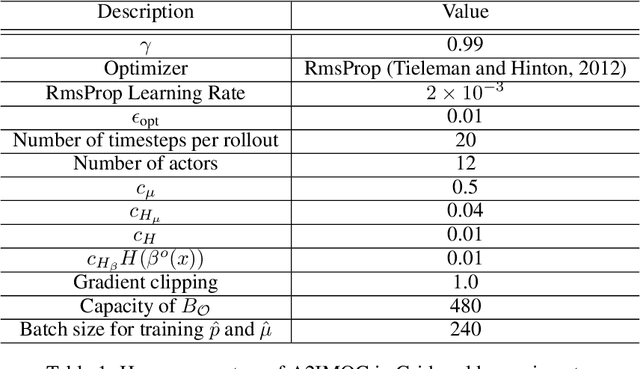
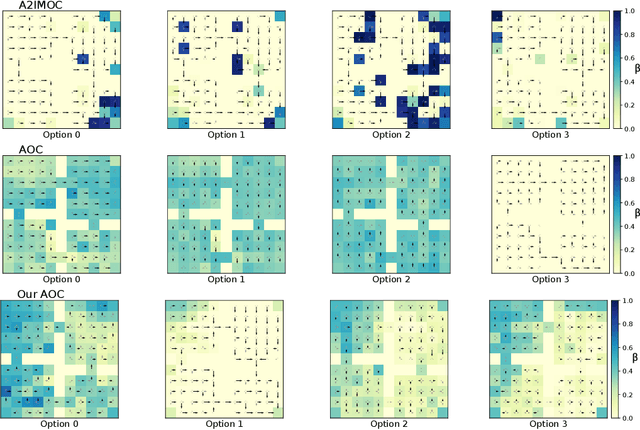
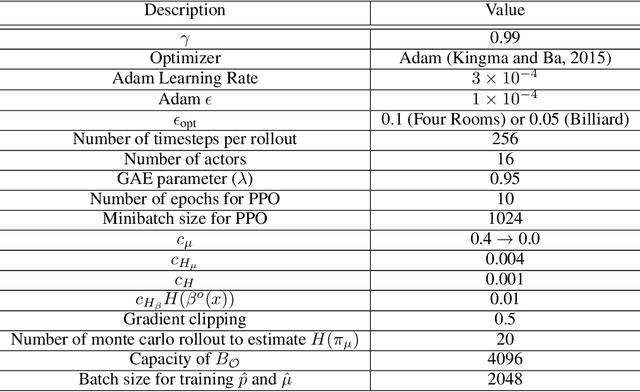
In this paper, we study the problem of autonomously discovering temporally abstracted actions, or options, for exploration in reinforcement learning. For learning diverse options suitable for exploration, we introduce the infomax termination objective defined as the mutual information between options and their corresponding state transitions. We derive a scalable optimization scheme for maximizing this objective via the termination condition of options, yielding the InfoMax Option Critic (IMOC) algorithm. Through illustrative experiments, we empirically show that IMOC learns diverse options and utilizes them for exploration. Moreover, we show that IMOC scales well to continuous control tasks.
Rogue-Gym: A New Challenge for Generalization in Reinforcement Learning
Apr 17, 2019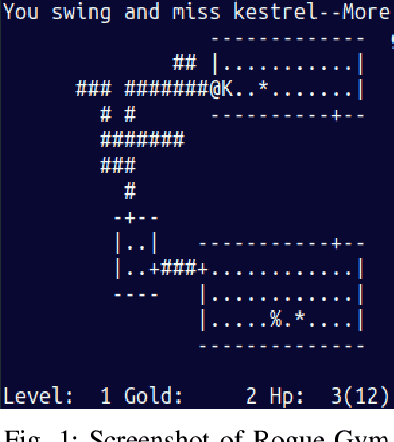
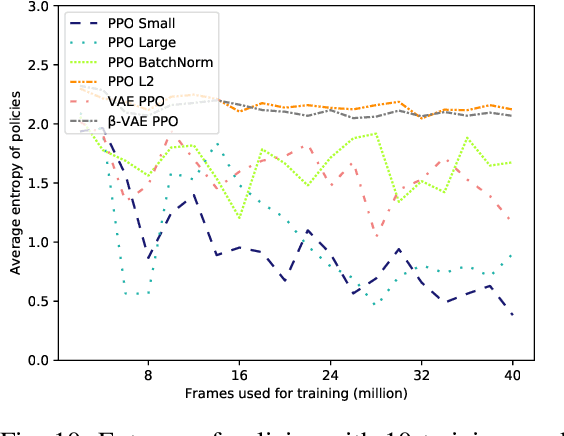
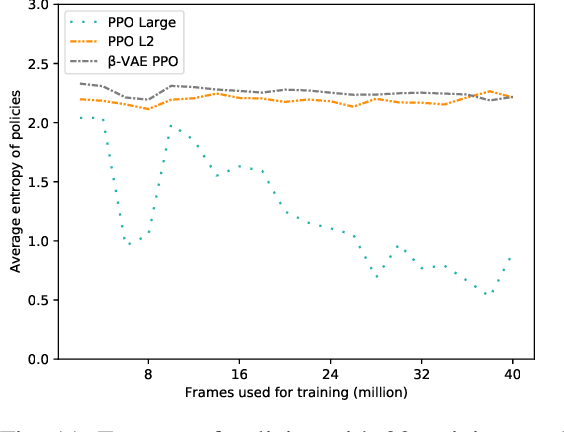
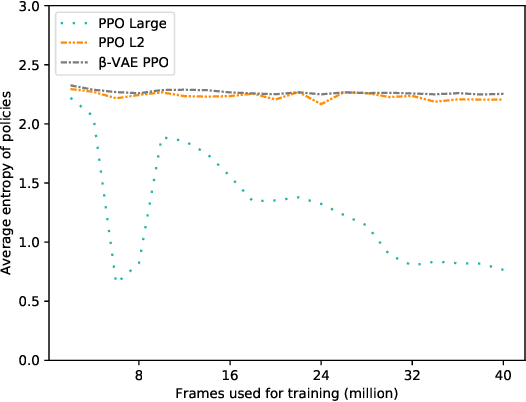
This paper presents Rogue-Gym, that enables agents to learn and play a subset of the original Rogue game with the OpenAI Gym interface. In roguelike games, a player explores a dungeon where each floor is two dimensional grid maze with enemies, golds, and downstairs. Because the map of a dungeon is different each time an agent starts a new game, learning in Rogue-Gym inevitably involves generalization of experiences, in a highly abstract manner. We argue that this generalization in reinforcement learning is a big challenge for AI agents. Recently, deep reinforcement learning (DRL) has succeeded in many games. However, it has been pointed out that agents trained by DRL methods often overfit to the training environment. To investigate this problem, some research environments with procedural content generation have been proposed. Following these studies, we show that our Rogue-Gym imposes a new generalization problem of their policies. In our experiments, we evaluate a standard reinforcement learning method, PPO, with and without enhancements for generalization. The results show that some enhancements work effective, but that there is still a large room for improvement. Therefore, Rogue-Gym a is a new challenging domain for further studies.